5
Distributional Dynamic Programming
Markov decision processes model the dynamics of an agent exerting control
over its environment. Once the agent’s policy is selected, a Markov decision
process gives rise to a sequential system whose behavior we would like to char-
acterize. In particular, policy evaluation describes the process of determining
the returns obtained from following a policy
π
. Algorithmically, this translates
into the problem of computing the value or return-distribution function given
the parameters of the Markov decision process and the agent’s policy.
Computing the return-distribution function requires being able to describe
the output of the algorithm in terms of atomic objects (depending on the pro-
gramming language, these may be bits, floating point numbers, vectors, or even
functions). This is challenging because in general, return distributions take on a
continuum of values (i.e., they are infinite-dimensional objects). By contrast,
the expected return from a state
x
is described by a single real number. Defining
an algorithm that computes return-distribution functions first requires us to
decide how we represent probability distributions in memory, knowing that
some approximation error must be incurred if we want to keep things finite.
This chapter takes a look at different representations of probability distribu-
tions as they relate to the problem of computing return-distribution functions.
We will see that, unlike the relatively straightforward problem of computing
value functions, there is no obviously best representation for return-distribution
functions and that different finite-memory representations offer different advan-
tages. We will also see that making effective use of different representations
requires different algorithms.
5.1 Computational Model
As before, we assume that the environment is described as a finite-state, finite-
action Markov decision process. We write
N
X
and
N
A
for the size of the state
and action spaces
X
and
A
. When describing algorithms in this chapter, we will
Draft version. 115
116 Chapter 5
further assume that the reward distributions
P
R
(
· | x, a
) are supported on a finite
set
R
of size
N
R
; we discuss a way of lifting this assumption in Remark 5.1.
Of note, having finitely many rewards guarantees the existence of an interval
[
V
min
, V
max
] within which the returns lie.
35
We measure the complexity of a
particular algorithm in terms of the number of atomic instructions or memory
words it requires, assuming that these can reasonably be implemented in a
physical computer, as described by the random-access machine (RAM) model
of computation (Cormen et al. 2001).
In classical reinforcement learning, linear algebra provides a simple algorithm
for computing the value function of a policy
π
. In vector notation, the Bellman
equation is
V
π
= r
π
+ γP
π
V
π
, (5.1)
where the transition function
P
π
is represented as an
N
X
-dimensional square
stochastic matrix, and
r
π
is an
N
X
-dimensional vector. With some matrix algebra,
we deduce that
V
π
= r
π
+ γP
π
V
π
⇐⇒ (I −γP
π
)V
π
= r
π
⇐⇒ V
π
= (I −γP
π
)
−1
r
π
. (5.2)
The computational cost of determining
V
π
is dominated by the matrix inversion,
requiring
O
(
N
3
X
) operations. The result is exact. The matrix
P
π
and the vector
r
π
are constructed entry-wise by writing expectations as sums:
P
π
(x
0
| x) =
X
a∈A
π(a | x)P
X
(x
0
| x, a)
r
π
(x) =
X
a∈A
X
r∈R
π(a | x)P
R
(r | x, a) ×r .
When the matrix inversion is undesirable, the value function can instead be
found by dynamic programming. Dynamic programming describes a wide vari-
ety of computational methods that find the solution to a given problem by
caching intermediate results. In reinforcement learning, the dynamic program-
ming approach for finding the value function
V
π
, also called iterative policy
evaluation, begins with an initial estimate V
0
∈R
X
and successively computes
V
k+1
= T
π
V
k
for
k
= 1
,
2
, . . .
, until some desired number of iterations
K
have been performed
or some stopping criterion is reached. This is possible because, when
X, A
, and
35.
We can always take
R
min
and
R
max
to be the smallest and largest possible rewards, respectively.
Draft version.

Distributional Dynamic Programming 117
R are all finite, the Bellman operator can be written in terms of sums:
(T
π
V
k
)(x) =
X
a∈A
X
r∈R
X
x
0
∈X
P
π
(A = a, R = r, X
0
= x
0
| X = x)
| {z }
π(a | x)P
X
(x
0
| x,a)P
R
(r | x,a)
r + γV
k
(x
0
)
. (5.3)
A naive implementation expresses these sums as nested for loops. Since the new
value function must be computed at all states, this naive implementation requires
on the order of
N
=
N
2
X
N
A
N
R
operations. We can do better by implementing it
in terms of vector operations:
V
k+1
= r
π
+ γP
π
V
k
, (5.4)
where
V
k
is stored in memory as an
N
X
-dimensional vector. A single appli-
cation of the Bellman operator with vectors and matrices requires
O
(
N
2
X
N
A
+
N
X
N
A
N
R
) operations for computing
r
π
and
P
π
, and
O
(
N
2
X
) operations for the
matrix-vector multiplication. As
r
π
and
P
π
do not need to be recomputed
between iterations, the dominant cost of this process comes from the successive
matrix multiplications, requiring O(KN
2
X
) operations.
36
In general, the iterates (
V
k
)
k≥0
will not reach
V
π
after any finite number of
iterations. However, the contractive nature of the Bellman operator allows us to
bound the distance from any iterate to the fixed point V
π
.
Proposition 5.1.
Let
V
0
∈R
X
be an initial value function and consider the
iterates
V
k+1
= T
π
V
k
. (5.5)
For any ε > 0, if we take
K
ε
≥
log
1
ε
+ log(kV
0
−V
π
k
∞
)
log
1
γ
,
then for all k ≥K
ε
, we have that
kV
k
−V
π
k
∞
≤ε .
For V
0
= 0, the dependency on V
π
can be simplified by noting that
log(kV
0
−V
π
k
∞
) = log(kV
π
k
∞
) ≤log
max(|V
min
|, |V
max
|)
. 4
Proof.
Since
T
π
is a contraction mapping with respect to the
L
∞
metric with con-
traction modulus
γ
(Proposition 4.4), and
V
π
is its fixed point (Proposition 2.12),
36.
Assuming that the number of states
N
X
is large compared to the number of actions
N
A
and
rewards
N
R
. For transition functions with special structure (sparsity, low rank, etc.), one can hope
to do even better.
Draft version.

118 Chapter 5
we have for any k ≥1
kV
k
−V
π
k
∞
= kT
π
V
k−1
−T
π
V
π
k
∞
≤γkV
k−1
−V
π
k
∞
,
and so by induction we have
kV
k
−V
π
k
∞
≤γ
k
kV
0
−V
π
k
∞
.
Setting the right-hand side to be less than or equal to
ε
and rearranging gives
the required inequality for K
ε
.
From Proposition 5.1, we conclude that we can obtain an
ε
-approximation
to
V
π
in
O
(
K
ε
N
2
X
) operations, by applying the Bellman operator
K
ε
times to
an initial value function
V
0
= 0. Since the iterate
V
k
can be represented as an
N
X
-dimensional vector and is the only object that the algorithm needs to store in
memory (other than the description of the MDP itself), this shows that iterative
policy evaluation can approximate V
π
efficiently.
5.2 Representing Return-Distribution Functions
Now, let us consider what happens in distributional reinforcement learning.
As with any computational problem, we first must decide on a data structure
that our algorithms operate on. The heart of our data structure is a scheme for
representing return-distribution functions in memory. We call such a scheme a
probability distribution representation.
Definition 5.2.
A probability distribution representation
F
, or simply repre-
sentation, is a collection of probability distributions indexed by a parameter
θ
from some set of allowed parameters Θ:
F =
P
θ
∈P (R) : θ ∈Θ
. 4
Example 5.3.
The Bernoulli representation is the set of all Bernoulli distribu-
tions:
F
B
=
(1 − p)δ
0
+ pδ
1
: p ∈[0, 1]
. 4
Example 5.4.
The uniform representation is the set of all uniform distributions
on finite-length intervals:
F
U
=
U([a, b]) : a, b ∈R, a < b
. 4
We represent return functions using a table of probability distributions, each
associated with a given state and described in our chosen representation. For
example, a uniform return function is described in memory by a table of 2
N
X
numbers, corresponding to the upper and lower ends of the distribution at each
state. By extension, we call such a table a representation of return-distribution
Draft version.

Distributional Dynamic Programming 119
functions. Formally, for a representation
F
, the space of representable return
functions is F
X
.
With this data structure in mind, let us consider the procedure (introduced by
Equation 4.10) that approximates the return function
η
π
by repeatedly applying
the distributional Bellman operator:
η
k+1
= T
π
η
k
. (5.6)
Because an operator is an abstract object, Equation 5.6 describes a mathematical
procedure, rather than a computer program. To obtain the latter, we begin by
expressing the distributional Bellman operator as a sum, analogous to Equation
5.3. Recall that the distributional operator is defined by an expectation over the
random variables R and X
0
:
(T
π
η)(x) = E
π
[(b
R,γ
)
#
η(X
0
) |X = x] . (5.7)
Here, the expectation describes a mixture of pushforward distributions. By
writing this expectation in full, we find that this mixture is given by
T
π
η
(x) =
X
a∈A
X
r∈R
X
x
0
∈X
P
π
A = a, R = r, X
0
= x
0
| X = x
(b
r,γ
)
#
η(x
0
) . (5.8)
The pushforward operation scales and then shifts (by
γ
and
r
, respectively)
the support of the probability distribution
η
(
x
0
), as depicted in Figure 2.5.
Implementing the distributional Bellman operator therefore requires being able
to efficiently perform the shift-and-scale operation and compute mixtures of
probability distributions; we caught a glimpse of what that might entail when
we derived categorical temporal-difference learning in Chapter 3.
Cumulative distribution functions allow us to rewrite Equations 5.7–5.8 in
terms of vector-like objects, providing a nice parallel with the usual vector
notation for the expected-value setting. Let us write
F
η
(
x, z
) =
F
η(x)
(
z
) to denote
the cumulative distribution function of
η
(
x
). We can equally express Equation
5.7 as
37
(T
π
F
η
)(x, z) = E
π
h
F
η
X
0
,
z−R
γ
| X = x
i
. (5.9)
As a weighted sum of cumulative distribution functions, Equation 5.9 is
(T
π
F
η
)(x, z) =
X
a∈A
X
r∈R
X
x
0
∈X
P
π
A = a, R = r, X
0
= x
0
| X = x
F
η
x
0
,
z−r
γ
. (5.10)
Similar to Equation 5.1, we can set
F
η
=
F
η
π
on both sides of Equation 5.10 to
obtain the linear system:
F
η
π
(x, z) =
X
a∈A
X
r∈R
X
x
0
∈X
P
π
A = a, R = r, X
0
= x
0
| X = x
F
η
π
x
0
,
z−r
γ
.
37.
With Chapter 4 in mind, note that we are overloading operator notation when we apply
T
π
to
collections of cumulative distribution functions, rather than return-distribution functions.
Draft version.
120 Chapter 5
However, this particular set of equations is infinite-dimensional. This is because
cumulative distribution functions are themselves infinite-dimensional objects,
more specifically elements of the space of monotonically increasing functions
mapping
R
to [0
,
1]. Because of this, we cannot describe them in physical
memory, at least not on a modern-day computer. This gives a concrete argument
as to why we cannot simply “store” a probability distribution but must instead
use a probability distribution representation as our data structure. For the same
reason, a direct algebraic solution to Equation 5.10 is not possible, in contrast to
the expected-value setting (Equation 5.2). This justifies the need for a dynamic
programming method to approximate η
π
.
Creating an algorithm for computing the return-distribution function requires
us to implement the distributional Bellman operator in terms of our chosen
representation. Conversely, we should choose a representation that supports an
efficient implementation. Unlike the value function setting, however, there is
no single best representation – making this choice requires balancing available
memory, accuracy, and the downstream uses of the return-distribution function.
The rest of this chapter is dedicated to studying these trade-offs and developing
a theory of what makes for a good representation. Like Goldilocks faced with
her choices, we first consider the situation where memory and computation are
plentiful, then the use of normal distributions to construct a minimally viable
return-distribution function, before finally introducing fixed-size empirical
representations as a sensible and practical middle ground.
5.3 The Empirical Representation
Simple representations like the Bernoulli representation are ill-suited to describe,
say, the different outcomes in blackjack (Example 2.7) or the variations in
the return distributions from different policies (Example 2.9). Although there
are scenarios in which a representation with few parameters gives a reason-
able approximation, the most general-purpose algorithms for computing return
distributions should be based on representations that are sufficiently expressive.
To understand what “sufficiently expressive” might mean, let us consider
what it means to implement the iterative procedure
η
k+1
= T
π
η
k
. (5.11)
The most direct implementation is a for loop over the iteration number
k
=
0, 1, . . . , interleaving
(a) determining (T
π
η
k
)(x) for each x ∈X, and
(b) expressing the outcome as a return-distribution function η
k+1
∈F .
Draft version.
Distributional Dynamic Programming 121
The first step of this procedure is an algorithm that emulates the operator
T
π
,
which we may call the operator-algorithm. When used as part of the
for
loop,
the output of this operator-algorithm at iteration
k
becomes the input at iteration
k
+ 1. As such, it is desirable for the inputs and outputs of the operator-algorithm
to have the same type: given as input a return function represented by
F
, the
operator-algorithm should produce a new return function that is also represented
by
F
. A prerequisite is that the representation
F
be closed under the operator
T
π
, in the sense that
η ∈F
X
=⇒ T
π
η ∈F
X
. (5.12)
The empirical representation satisfies this desideratum.
Definition 5.5.
The empirical representation is the set
F
E
of empirical
distributions
F
E
=
(
m
X
i=1
p
i
δ
θ
i
: m ∈N
+
, θ
i
∈R, p
i
≥0,
m
X
i=1
p
i
= 1
)
. 4
An empirical distribution
ν ∈F
E
can be stored in memory as a finite list of
pairs
θ
i
, p
i
m
i=1
. We call individual elements of such a distribution particles,
each consisting of a probability and a location. Notationally, we extend the
empirical representation to return distributions by writing
η(x) =
m(x)
X
i=1
p
i
(x)δ
θ
i
(x)
(5.13)
for the return distribution corresponding to state x.
The application of the distributional Bellman operator to empirical proba-
bility distributions has a particular convenient form that we formalize with the
following lemma and proposition.
Lemma 5.6.
Let
ν ∈F
E
be an empirical distribution with parameters
m
and
(θ
i
, p
i
)
m
i=1
. For r ∈R and γ ∈R, we have
(b
r,γ
)
#
ν =
m
X
i=1
p
i
δ
r+γθ
i
. 4
In words, the application of the bootstrap function to an empirical distribution
ν
shifts and scales the locations of that distribution (see Exercise 5.7). This
property was implicit in our description of the pushforward operation in Chapter
2, and we made use of it (also implicitly) to derive the categorical temporal-
difference learning algorithm in Chapter 3.
Draft version.

122 Chapter 5
Proposition 5.7.
Provided that the set of possible rewards
R
is finite, the
empirical representation
F
E
is closed under
T
π
. In particular, if
η ∈F
X
E
is
a return-distribution with parameters
p
i
(x), θ
i
(x)
m(x)
i=1
: x ∈X
then
T
π
η
(x) =
X
a∈A
X
r∈R
X
x
0
∈X
P
π
(A = a, R = r, X
0
= x
0
| X = x)
m(x
0
)
X
i=1
p
i
(x
0
)δ
r+γθ
i
(x
0
)
.
(5.14)
4
Proof.
Pick a state
x ∈X
. For a triple (
a, r, x
0
)
∈A×R×X
, write
P
a,r,x
0
=
P
π
A = a, R = r, X
0
= x
0
| X = x
. Then,
(T
π
η)(x)
(a)
=
X
a∈A
X
r∈R
X
x
0
∈X
P
a,r,x
0
(b
r,γ
)
#
η(x
0
)
=
X
a∈A
X
r∈R
X
x
0
∈X
P
a,r,x
0
(b
r,γ
)
#
m(x
0
)
X
i=1
p
i
(x
0
)δ
θ
i
(x
0
)
(b)
=
X
a∈A
X
r∈R
X
x
0
∈X
P
a,r,x
0
m(x
0
)
X
i=1
p
i
(x
0
)δ
r+γθ
i
(x
0
)
≡
m
0
X
j=1
p
0
j
δ
θ
0
j
for some collection (
θ
0
j
, p
0
j
)
m
0
j=1
. Line (a) is Equation 5.8 and (b) follows from
Lemma 5.6. We conclude that (
T
π
η
)(
x
)
∈F
E
, and hence
F
E
is closed under
T
π
.
Algorithm 5.1 uses Proposition 5.7 to compute the application of the distri-
butional Bellman operator to any
η
represented by
F
E
. It implements Equation
5.14 almost verbatim, with two simplifications. First, it uses the fact that the
particle locations for a distribution (
T
π
η
)(
x
) only depend on
r
and
x
0
but not
on
a
. This allows us to produce a single particle for each reward-next-state
pair. Second, it also encodes the fact that the return is 0 from the terminal state,
making dynamic programming more effective from this state (Exercise 5.3 asks
you to justify this claim). Since the output of Algorithm 5.1 is also a return
function from
F
E
, we can use it to produce the iterates
η
1
, η
2
, . . .
from an initial
return function η
0
∈F
X
E
.
Because
F
E
is closed under
T
π
, we can analyze the behavior of this
procedure using the theory of contraction mappings (Chapter 4). Here we
bound the number of iterations needed to obtain an
ε
-approximation to the
Draft version.

Distributional Dynamic Programming 123
Algorithm 5.1: Empirical representation distributional Bellman
operator
Algorithm parameters: η, expressed as θ =
θ
i
(x), p
i
(x)
m(x)
i=1
: x ∈X
foreach x ∈X do
θ
0
(x) ←Empty List
foreach x
0
∈X do
foreach r ∈R do
α
r,x
0
←
P
a∈A
π(a | x)P
R
(r | x, a)P
X
(x
0
| x, a)
if x
0
is terminal then
Append
r, α
r,x
0
to θ
0
(x)
else
for i = 1, …, m(x
0
) do
Append
r + γθ
i
(x
0
), α
r,x
0
p
i
(x
0
)
to θ
0
(x)
end for
end foreach
end foreach
end foreach
return θ
0
return-distribution function
η
π
, as measured by a supremum
p
-Wasserstein
metric.
Proposition 5.8.
Consider an initial return function
η
0
(
x
) =
δ
0
for all
x ∈X
and the dynamic programming approach that iteratively computes
η
k+1
= T
π
η
k
by means of Algorithm 5.1. Let ε > 0 and let
K
ε
≥
log
1
ε
+ log
max(|V
min
|, |V
max
|)
log
1
γ
.
Then, for all k ≥K
ε
, we have that
w
p
(η
k
, η
π
) ≤ε ∀p ∈[1, ∞] ,
where w
p
is the supremum p-Wasserstein distance. 4
Proof.
Similar to the proof of Proposition 5.1, since
T
π
is a contraction map-
ping with respect to the
w
p
metric with contraction modulus
γ
(Proposition 4.15),
Draft version.

124 Chapter 5
and η
π
is its fixed point (Propositions 2.17 and 4.9), we can deduce
w
p
(η
k
, η
π
) ≤γ
k
w
p
(η
0
, η
π
) .
Since
η
0
=
δ
0
and
η
π
is supported on [
V
min
, V
max
], we can upper-bound
w
p
(
η
0
, η
π
)
by
max
(
|V
min
|, |V
max
|
). Setting the right-hand side to be less than or equal to
ε
and rearranging gives the required inequality for K
ε
.
Although we state Proposition 5.8 in terms of
p
-Wasserstein distance for
concreteness, we can also obtain similar results more generally for probability
metrics under which the distributional Bellman operator is contractive.
The analysis of this section shows that the empirical representation is suffi-
ciently expressive to support an iterative procedure for approximating the return
function
η
π
to an arbitrary precision, due to being closed under the distributional
Bellman operator. This result is perhaps somewhat surprising: even if
η
π
< F
E
,
we are able to obtain an arbitrarily accurate approximation within F
E
.
Example 5.9.
Consider the single-state Markov decision process of Example
2.10, with Bernoulli reward distribution
U
(
{
0
,
1
}
) and discount factor
γ
=
1
/2
.
Beginning with η
0
(x), the return distributions of the iterates
η
k+1
= T
π
η
k
are a collection of uniformly weighted, evenly spaced Dirac deltas:
η
k
(x) =
1
2
k
2
k
−1
X
i=0
δ
θ
i
, θ
i
=
i
2
k−1
. (5.15)
As suggested by Figure 2.3, the sequence of distributions
η
k
(x)
k≥0
converges
to the uniform distribution
U
([0
,
2]) in the
p
-Wasserstein distances, for all
p ∈[1, ∞]. However, this limit is not itself an empirical distribution. 4
The downside is that the algorithm is typically intractable for anything but a
small number of iterations
K
. This is because the lists that describe
η
k
may grow
exponentially in length with
K
, as shown in the example above. Even when
η
0
is initialized to be
δ
0
at all states (as in Proposition 5.8), representing the
k
th
iterate requires
O
N
k
X
N
k
R
particles per state, corresponding to all achievable
discounted returns of length
k
.
38
This is somehow unavoidable: in a certain
sense, the problem of computing return functions is NP-hard (see Remark 5.2).
This motivates the need for a more complex procedure that forgoes closedness
in favor of tractability.
38. A smarter implementation only requires O
N
k
R
particles per state. See Exercise 5.8.
Draft version.
Distributional Dynamic Programming 125
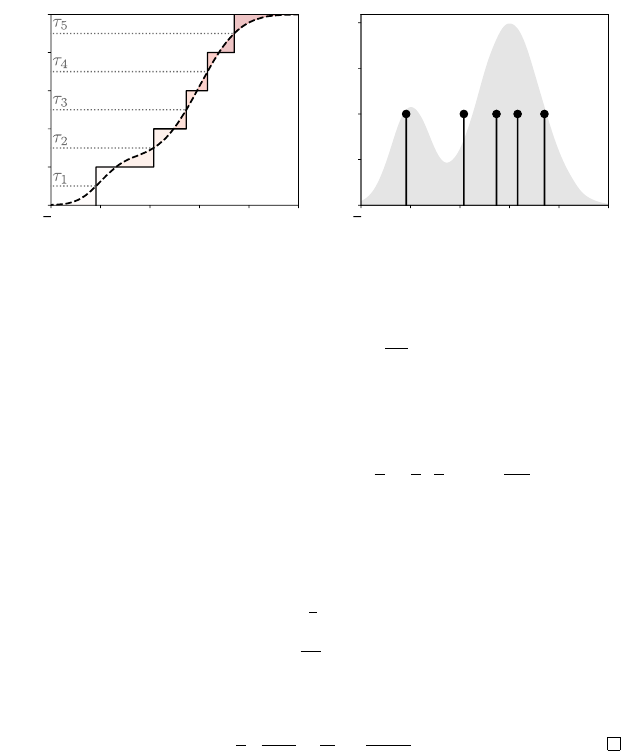
5.4 The Normal Representation
To avoid the computational costs associated with unbounded memory usage, we
may restrict ourselves to probability distributions described by a fixed number
of parameters. A simple choice is to model the return with a normal distribution,
which requires only two parameters per state: a mean µ and variance σ
2
.
Definition 5.10. The normal representation is the set of normal distributions
F
N
=
N(µ, σ
2
) : µ ∈R, σ
2
≥0
. 4
With this representation, a return function is described by a total of 2
N
X
parameters.
More often than not, however, the random returns are not normally distributed.
This may be because the rewards themselves are not normally distributed, or
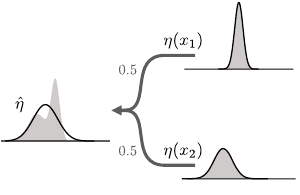
because the transition kernel is stochastic. Figure 5.1 illustrates the effect of
the distributional Bellman operator on a normal return-distribution function
η
:
mixing the return distributions at successor states results in a mixture of normal
distributions, which is not normally distributed except in trivial situations. In
other words, the normal representation
F
N
is generally not closed under the
distributional Bellman operator.
Rather than represent the return distribution with high accuracy, as with the
empirical distribution, let us consider the more modest goal of determining the
best normal approximation to the return-distribution function
η
π
. We define
“best normal approximation” as
ˆη
π
(x) = N
V
π
(x), Var
G
π
(x)
. (5.16)
Given that a normal distribution is parameterized by its mean and variance, this
is an obviously sensible choice. In some cases, this choice can also be justified
by arguing that
ˆη
π
(
x
) is the normal distribution closest to
η
π
(
x
) in terms of what
is called the Kullback–Leibler divergence.
39
As we now show, this choice also
leads to a particularly efficient algorithm for computing ˆη
π
.
We will construct an iterative procedure that operates on return functions
from a normal representation and converges to
ˆη
π
. We start with the random
variable operator
T
π
G
(x)
D
= R + γG(X
0
), X = x , (5.17)
39.
Technically, this is only true when the return distribution
η
π
(
x
) has a probability density function.
When
η
π
(
x
) does not have a density, a similar argument can be made in terms with the cross-entropy
loss; see Exercises 5.5 and 5.6.
Draft version.
126 Chapter 5
Return
Return
Return
Figure 5.1
Applying the distributional Bellman oper-
ator to a return function
η
described by the
normal representation generally produces
return distributions that are not normally
distributed. Here, a uniform mixture of two
normal distributions (shown as probability
densities) results in a bimodal distribution
(in light gray). The best normal approxi-
mation
ˆη
to that distribution is depicted by
the solid curve.
and take expectations on both sides of the equation:
40
E
(T
π
G)(x)
= E
π
h
R + γE[G(X
0
) | X
0
] | X = x
i
= E
π
[R | X = x] + γ E
π
[E[G(X
0
) | X
0
] | X = x]
= E
π
[R | X = x] + γ
X
x
0
∈X
P
π
(X
0
= x
0
| X = x) E[G(x
0
)] , (5.18)
where the last step follows from the assumption that the random variables
G
are
independent of the next-state
X
0
. When applied to the return-variable function
G
π
, Equation 5.18 is none other than the classical Bellman equation.
The same technique allows us to relate the variance of (
T
π
G
)(
x
) to the
next-state variances. For a random variable Z, recall that
Var(Z) = E
(Z −E[Z])
2
.
The random reward
R
and next-state
X
0
are by definition conditionally indepen-
dent given
X
and
A
. However, to simplify the exposition, we assume that they
are also conditionally independent given only
X
(in Chapter 8, we will see how
this assumption can be avoided).
Let us use the notation
Var
π
to make explicit the dependency of certain
random variables on the sample transition model, analogous to our use of
E
π
.
Denote the value function corresponding to G by V(x) = E[G(x)]. We have
Var
(T
π
G)(x)
= Var
π
R + γG(X
0
) | X = x
= Var
π
R | X = x
+ Var
π
γG(X
0
) | X = x
= Var
π
R | X = x
+ γ
2
Var
π
G(X
0
) | X = x
= Var
π
R | X = x
+ γ
2
Var
π
V(X
0
) | X = x
40.
In Equation 5.18, some of the expectations are taken solely with respect to the sample transition
model, which we denote by
E
π
as usual. The expectation with respect to the random variable
G
, on
the other hand, is not part of the model; we use the unsubscripted E to emphasize this point.
Draft version.
Distributional Dynamic Programming 127
+ γ
2
X
x
0
∈X
P
π
(X
0
= x
0
| X = x)Var
G(x
0
)
, (5.19)
where the last line follows by the law of total variance:
Var(A) = Var
E[A | B]
+ E
Var[A | B]
.
Equation 5.19 shows how to compute the variances of the return function
T
π
G
.
Specifically, these variances depend on the reward variance, the variance in
next-state values, and the expected next-state variances. When
G
=
G
π
, this is
the Bellman equation for the variance of the random return. Writing
σ
2
π
(
x
) =
Var
G
π
(x)
, we obtain
σ
2
π
(x) = Var
π
(R | X = x) + γ
2
Var
π
V
π
(X
0
) | X = x
+ γ
2
X
x
0
∈X
P
π
(X
0
= x
0
| X = x)σ
2
π
(x) . (5.20)
We now combine the results above to obtain a dynamic programming proce-
dure for finding
ˆη
π
. For each state
x ∈X
, let us denote by
µ
0
(
x
) and
σ
2
0
(
x
) the
parameters of a return-distribution distribution
η
0
with
η
0
(
x
) =
N
µ
0
(
x
)
, σ
2
0
(
x
)
.
For all x, we simultaneously compute
µ
k+1
(x) = E
π
[R + γµ
k
(X
0
) | X = x] (5.21)
σ
2
k+1
(x) = Var
π
R | X = x
+ γ
2
Var
π
µ
k
(X
0
) | X = x
+ γ
2
E
π
[σ
2
k
(X
0
) | X = x] .
(5.22)
We can view these two updates as the implementation of a bona fide operator
over the space of normal return-distribution functions. Indeed, we can associate
to each iteration the return function
η
k
(x) = N
µ
k
(x), σ
2
k
(x)
∈F
N
.
Analyzing the behavior of the sequence (
η
k
)
k≥0
require some care, but we
shall see in Chapter 8 that the iterates converge to the best approximation
ˆη
π
(Equation 5.16), in the sense that for all x ∈X,
µ
k
(x) →V
π
(x) σ
2
k
(x) →Var
G
π
(x)
.
This derivation shows that the normal representation can be used to create a
tractable algorithm for approximating the return distribution. However, in our
work, we have found that the normal representation rarely gives a satisfying
depiction of the agent’s interactions with its environment; it is not sufficiently
expressive. In many problems, outcomes are discrete in nature: success or
failure, food or hunger, forward motion or fall. This arises in video games in
which the game ends once the player’s last life is spent. Timing is also critical:
to catch the diamond, key, or mushroom, the agent must press “jump” at just the
Draft version.

128 Chapter 5
right moment, again leading to discrete outcomes. Even in relatively continuous
systems, such as the application of reinforcement learning to stratospheric
balloon flight, the return distributions tend to be skewed or multimodal. In short,
normal distributions are a poor fit for the wide gamut of problems found in
reinforcement learning.
5.5 Fixed-Size Empirical Representations
The empirical representation is expressive because it can use more particles to
describe more complex probability distributions. This “blank check” approach
to memory and computation, however, results in an intractable algorithm. On
the other hand, the simple normal distribution is rarely sufficient to give a
good approximation of the return distribution. A good middle ground is to
preserve the form of the empirical representation while imposing a limit on its
expressivity. Our approach is to fix the number and type of particles used to
represent probability distributions.
Definition 5.11.
The
m
-quantile representation parameterizes the location of
m equally weighted particles. That is,
F
Q,m
=
(
1
m
m
X
i=1
δ
θ
i
: θ
i
∈R
)
. 4
Definition 5.12.
Given a collection of
m
evenly spaced locations
θ
1
< ···< θ
m
,
the
m
-categorical representation parameterizes the probability of
m
particles at
these fixed locations:
F
C,m
=
(
m
X
i=1
p
i
δ
θ
i
: p
i
≥0,
m
X
i=1
p
i
= 1
)
.
We denote the stride between successive particles by ς
m
=
θ
m
−θ
1
m−1
. 4
This definition corresponds to the categorical representation used in Chapter
3. Note that because of the constraint that probabilities should sum to 1, a
m
-
categorical distribution is described by
m −
1 parameters. In addition, although
the representation depends on the choice of locations
θ
1
, …, θ
m
, we omit this
dependence in the notation F
C,m
to keep things concise.
In our definition of the
m
-categorical representation, we assume that the
locations (
θ
i
)
m
i=1
are given a priori and not part of the description of a particular
probability distribution. This is sensible when we consider that algorithms such
as categorical temporal-difference learning use the same set of locations to
describe distributions at different states and keep these locations fixed across
the learning process. For example, a common choice is
θ
1
=
V
min
and
θ
m
=
V
max
.
Draft version.
Distributional Dynamic Programming 129
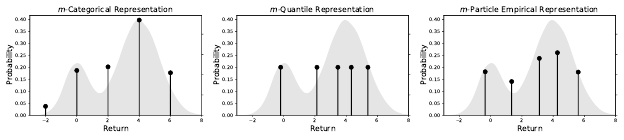
Figure 5.2
A distribution
ν
(in light gray), as approximated with a
m
-categorical,
m
-quantile, or
m-particle representation, for m = 5.
When it is desirable to adjust both the locations and probabilities of different
particles, we instead make use of the m-particle representation.
Definition 5.13.
The
m
-particle representation parameterizes both the proba-
bility and location of m particles:
F
E,m
=
(
m
X
i=1
p
i
δ
θ
i
: θ
i
∈R, p
i
≥0,
m
X
i=1
p
i
= 1
)
.
The
m
-particle representation contains both the
m
-quantile representation and
the
m
-categorical representation; a distribution from
F
E,m
is defined by 2
m −
1
parameters. 4
Mathematically, all three representations described above are subsets of
the empirical representation
F
E
; accordingly, we call them fixed-size empiri-
cal representations. Fixed-size empirical representations are flexible and can
approximate both continuous and discrete outcome distributions (Figure 5.2).
The categorical representation is so called because it models the probability
of a set of fixed outcomes. This is somewhat of a misnomer: the “categories”
are not arbitrary but instead correspond to specific real values. The quantile
representation is named for its relationship to the quantiles of the return distri-
bution. Although it might seem like the
m
-particle representation is a strictly
superior choice, we will see that committing to either fixed locations or fixed
probabilities simplifies algorithmic design. For an equal number of parameters,
it is also not clear whether one should prefer
m
fully parameterized particles or,
say, 2m −1 uniformly weighted particles.
Like the normal representation, fixed-size empirical representations are not
closed under the distributional Bellman operator
T
π
. As discussed in Section
5.3, the consequence is that we cannot implement the iterative procedure
η
k+1
= T
π
η
k
Draft version.
130 Chapter 5
with such a representation. To get around this issue, let us now introduce
the notion of a projection operator: a mapping from the space of probability
distributions (or a subset thereof) to a desired representation
F
.
41
We denote
such an operator by
Π
F
: P(R) →F .
Definitionally, we require that projection operators satisfy, for any ν ∈F ,
Π
F
ν = ν .
We extend the notation Π
F
to the space of return-distribution functions:
Π
F
η
(x) = Π
F
η(x)
.
The categorical projection Π
c
, first encountered in Chapter 3, is one such
operator; we will study it in greater detail in the remainder of this chapter.
We also made implicit use of a projection step in deriving an algorithm for
the normal representation: at each iteration, we kept track of the mean and
variance of the process but discarded the rest of the distribution, so that the
return function iterates could be described with the normal representation.
Algorithmically, we introduce a projection step following the application of
T
π
, leading to a projected distributional Bellman operator Π
F
T
π
. By defini-
tion, this operator maps
F
to itself, allowing for the design of distributional
algorithms that represent each iterate of the sequence
η
k+1
= Π
F
T
π
η
k
using a bounded amount of memory. We will discuss such algorithmic con-
siderations in Section 5.7, after describing particular projection operators for
the categorical and quantile representations. Combined with numerical integra-
tion, the use of a projection step also makes it possible to perform dynamic
programming with continuous reward distributions (see Exercise 5.9).
5.6 The Projection Step
We now describe projection operators for the categorical and quantile represen-
tations, correspondingly called categorical projection and quantile projection.
In both cases, these operators can be seen as finding the best approximation to a
given probability distribution, as measured according to a specific probability
metric.
To begin, recall that for a probability metric
d
,
P
d
(
R
)
⊆P
(
R
) is the set of
probability distributions with finite mean and finite distance from the reference
41.
In Section 4.1, we defined an operator as mapping elements from a space to itself. The term
“projection operator” here is reasonable given that F ⊆P(R).
Draft version.
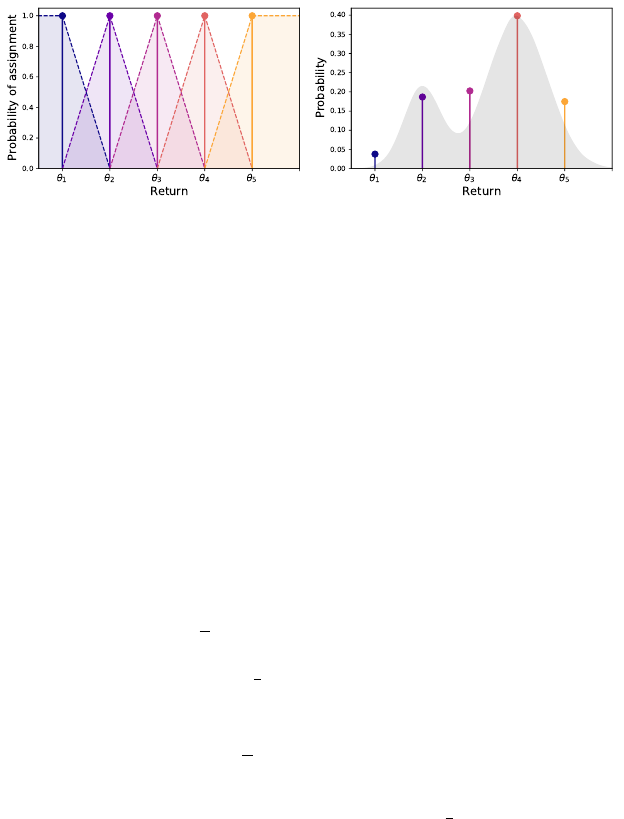
Distributional Dynamic Programming 131
Figure 5.3
Left
: The categorical projection assigns probability mass to each location according to
a triangular kernel (central locations) and half-triangular kernels (boundary locations).
Here,
m
= 5.
Right
: The
m
= 5 categorical projection of a given distribution, shown in
gray. Each Dirac delta is colored to match its kernel in the left panel.
distribution
δ
0
(Equation 4.26). For a representation
F ⊆P
d
(
R
), a
d
-projection
of
ν ∈P
d
(
R
) onto
F
is a function Π
F ,d
:
P
d
(
R
)
→F
that finds a distribution
ˆν ∈F that is d-closest to ν:
Π
F ,d
ν ∈arg min
ˆν∈F
d(ν, ˆν) . (5.23)
Although both the categorical and quantile projections that we present here
satisfy this definition, it is worth noting that in the most general setting, neither
the existence nor uniqueness of a
d
-projection Π
F ,d
is actually guaranteed (see
Remark 5.3). We lift the notion of a
d
-projection to return-distribution functions
in our usual manner; the d-projection of η ∈P
d
(R)
X
onto F
X
is
Π
F
X
,d
η
(x) = Π
F ,d
η(x)
.
When unambiguous, we overload notation and write Π
F ,d
η
to denote the
projection onto F
X
.
It is natural to think of the
d
-projection of the return-distribution function
η
onto
F
X
as the best achievable approximation within this representation,
measured in terms of
d
. We thus call Π
F ,d
ν
and Π
F
X
,d
η
the (
d, F
)-optimal
approximations to ν ∈P(R) and η, respectively.
Categorical projection.
In Chapter 3, we defined the categorical projection
Π
c
as assigning the probability mass
q
of a particle located at
z
to the two loca-
tions nearest to
z
in the fixed support
{θ
1
, . . . , θ
m
}
. Specifically, the categorical
projection assigns this mass
q
in (inverse) proportion to the distance to these
two neighbors. We now extend this idea to the case where we wish to more
generally project a distribution
ν ∈P
1
(
R
) onto the
m
-categorical representation.
Draft version.

132 Chapter 5
Given a probability distribution ν ∈P
1
(R), its categorical projection
Π
c
ν =
m
X
i=1
p
i
δ
θ
i
has parameters
p
i
= E
Z∼ν
h
h
i
ς
−1
m
Z −θ
i
i
, i = 1, . . . , m , (5.24)
for a set of functions
h
i
:
R →
[0
,
1] that we will define below. Here we write
p
i
in terms of an expectation rather than a sum, with the idea that this expectation
can be efficiently computed (this is the case when
ν
is itself a
m
-categorical
distribution).
When i = 2, . . . , m −1, the function h
i
is the triangular kernel
h
i
(z) = h(z) = max(0, 1 −|z|) .
We use this notation to describe the proportional assignment of probability mass
for the inner locations
θ
2
, . . . , θ
m−1
. One can verify that the triangular kernel
assigns probability mass from
ν
to the location
θ
i
in proportion to the distance
to its neighbors (Figure 5.3).
The parameters of the extreme locations are computed somewhat differently,
as these also capture the probability mass associated with values greater than
θ
m
and smaller than θ
1
. For these, we use the half-triangular kernels
h
1
(z) =
(
1 z ≤0
max(0, 1 −|z|) z > 0
h
m
(z) =
(
max(0, 1 −|z|) z ≤0
1 z > 0 .
Exercise 5.10 asks you to prove that the projection described here matches to
deterministic projection of Section 3.5.
Our derivation gives a mathematical formalization of the idea of assign-
ing proportional probability mass to the locations nearest to a given particle,
described in Chapter 3. In fact, it also describes the projection of
ν
in the Cramér
distance (
2
) onto the
m
-categorical representation. This is stated formally as
follows and proven in Remark 5.4.
Proposition 5.14.
Let
ν ∈P
1
(
R
). The
m
-categorical probability distri-
bution whose parameters are given by Equation 5.24 is the (unique)
2
-projection onto F
C,m
. 4
Quantile projection.
We call the quantile projection of a probability dis-
tribution of
ν ∈P
(
R
) a specific projection of
ν
in the 1-Wasserstein distance
(
w
1
) onto the
m
-quantile representation (Π
F
Q,m
,w
1
). With this choice of distance,
this projection can be expressed in closed form and is easily implemented. In
addition, we will see in Section 5.9 that it leads to a well-behaved dynamic
Draft version.
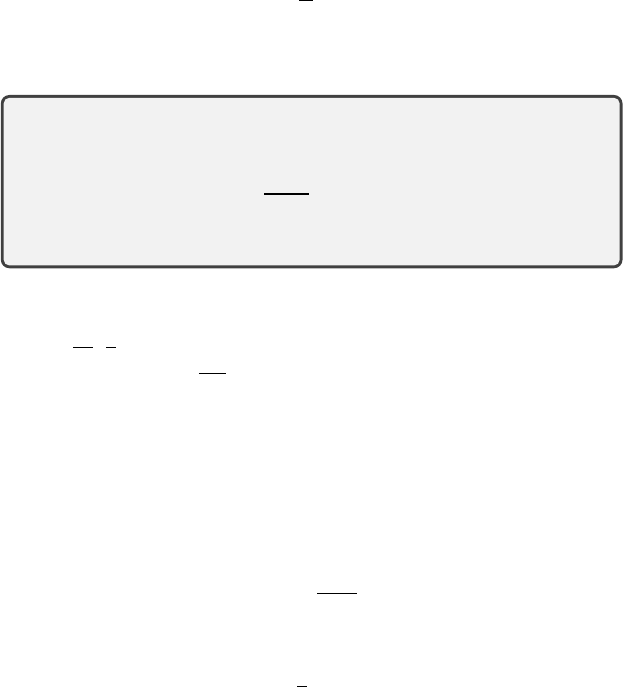
Distributional Dynamic Programming 133
programming algorithm. As with the categorical projection, we introduce the
shorthand Π
q
for the projection operator Π
F
Q,m
,w
1
.
Consider a probability distribution
ν ∈P
1
(
R
). We are interested in a proba-
bility distribution Π
q
ν ∈F
Q,m
that minimizes the 1-Wasserstein distance from
ν:
minimize w
1
(ν, ν
0
) subject to ν
0
∈F
Q,m
.
By definition, such a solution must take the form
Π
q
ν =
1
m
m
X
i=1
δ
θ
i
.
The following establishes that choosing (
θ
i
)
m
i=1
to be a particular set of quantiles
of ν yields a valid w
1
-projection of ν.
Proposition 5.15.
Let
ν ∈P
1
(
R
). The
m
-quantile probability distribution
whose parameters are given by
θ
i
= F
−1
ν
2i −1
2m
!
i = 1, . . . , m (5.25)
is a w
1
-projection of ν onto F
Q,m
. 4
Equation 5.25 arises because the
i
th particle of a
m
-quantile distribution is
“responsible” for the portion of the 1-Wasserstein distance measured on the
interval [
i−1
m
,
i
m
] (Figure 5.4). As formalized by the following lemma, the choice
of the midpoint quantile
2i−1
2m
minimizes the 1-Wasserstein distance to
ν
on this
interval.
Lemma 5.16.
Let
ν ∈P
1
(
R
) with cumulative distribution function
F
ν
. Let
0 ≤a < b ≤1. Then a solution to
min
θ∈R
Z
b
a
F
−1
ν
(τ) −θ
dτ (5.26)
is given by the quantile midpoint
θ = F
−1
ν
a + b
2
!
. 4
The proof is given as Remark 5.5.
Proof of Proposition 5.15.
Let
ν
0
=
1
m
m
P
i=1
δ
θ
i
be a
m
-quantile distribution.
Assume that its locations are sorted: that is,
θ
1
≤θ
2
≤···≤θ
m
. For
τ ∈
(0
,
1),
its inverse cumulative distribution function is
F
−1
ν
0
(τ) = θ
dτme
.
Draft version.
134 Chapter 5
2 0 2 4 6 8
Return
0.0
0.2
0.4
0.6
0.8
1.0
Cumulative Probability
2 0 2 4 6 8
Return
0.0
0.1
0.2
0.3
0.4
Probability
Figure 5.4
Left
: The quantile projection finds the quantiles of the distribution
ν
(the dashed line
depicts its cumulative distribution function) for
τ
i
=
2i−1
2m
, i
= 1
, . . . m
. The shaded area
corresponds to the 1-Wasserstein distance between
ν
and its quantile projection Π
q
ν
(solid line,
m
= 5).
Right
: The optimal (
w
1
, F
Q,m
)-approximation to the distribution
ν
,
shown in gray.
This function is constant on the intervals (0
,
1
m
)
,
[
1
m
,
2
m
)
, . . . ,
[
m−1
m
,
1). The 1-
Wasserstein distance between
ν
and
ν
0
therefore decomposes into a sum of
m
terms:
w
1
(ν, ν
0
) =
Z
1
0
F
−1
ν
(τ) − F
−1
ν
0
(τ)
dτ
=
m
X
i=1
Z
i
m
(i−1)
m
F
−1
ν
(τ) −θ
i
dτ .
By Lemma 5.16, the
i
th term of the sum is minimized by the quantile midpoint
F
−1
ν
(τ
i
), where
τ
i
=
1
2
"
i −1
m
+
i
m
#
=
2i −1
2m
.
Unlike the categorical-Cramér case, in general, there is not a unique
m
-
quantile distribution
ν
0
∈F
Q,m
that is closest in
w
1
to a given distribution
ν ∈
P
1
(R). The following example illustrates how the issue might take shape.
Example 5.17. Consider the set of Dirac distributions
F
Q,1
= {δ
θ
: θ ∈R}.
Draft version.

Distributional Dynamic Programming 135
Let
ν
=
1
2
δ
0
+
1
2
δ
1
be the Bernoulli(
1
/2
) distribution. For any
θ ∈
[0
,
1],
δ
θ
∈F
Q,1
is an optimal (w
1
, F
Q,1
)-approximation to ν:
w
1
(ν, δ
θ
) = min
ν
0
∈F
Q,1
w
1
(ν, ν
0
) ,
Perhaps surprisingly, this shows that the distribution
δ
1
/2
, halfway between the
two possible outcomes and an intuitive one-particle approximation to
ν
, is a no
better choice than δ
0
when measured in terms of 1-Wasserstein distance. 4
5.7 Distributional Dynamic Programming
We embed the projected Bellman operator in an
for
loop to obtain an algorithmic
template for approximating the return function (Algorithm 5.2). We call this
template distributional dynamic programming (DDP),
42
as it computes
η
k+1
= Π
F
T
π
η
k
(5.27)
by iteratively applying a projected distributional Bellman operator. A special
case is when the representation is closed under
T
π
, in which case no projection
is needed. However, by contrast with Equation 5.6, the use of a projection allows
us to consider algorithms for a greater variety of representations. Summarizing
the results of the previous sections, instantiating this template involves three
parts:
Choice of representation. We first need a probability distribution represen-
tation
F
. Provided that this representation uses finitely many parameters, this
enables us to store return functions in memory, using the implied mapping from
parameters to probability distributions.
Update step.
We then need a subroutine for computing a single application
of the distributional Bellman operator to a return function represented by
F
(Equation 5.8).
Projection step.
We finally need a subroutine that maps the outputs of the
update step to probability distributions in
F
. In particular, when Π
F
is a
d
-projection, this involves finding an optimal (
d, F
)-approximation at each
iteration.
For empirical representations, including the categorical and quantile repre-
sentations, the update step can be implemented by Algorithm 5.1. That is, when
there are finitely many rewards, the output of
T
π
applied to any
m
-particle
representation is a collection of empirical distributions:
η ∈F
E,m
=⇒ T
π
η ∈F
E
.
42.
More precisely, this is distributional dynamic programming applied to the problem of policy
evaluation. A sensible but less memorable alternative is “iterative distributional policy evaluation.”
Draft version.

136 Chapter 5
Algorithm 5.2: Distributional dynamic programming
Algorithm parameters: representation F , projection Π
F
desired number of iterations K,
initial return function η
0
∈F
X
Initialize η ←η
0
for k = 1, . . . , K do
η
0
←T
π
η Algorithm 5.1
foreach state x ∈X do
η(x) ←(Π
F
η
0
)(x)
end foreach
end for
return η
As a consequence, it is sufficient to have an efficient subroutine for projecting
empirical distributions back to F
C,m
, F
Q,m
, or F
E,m
.
For example, consider the projection of the empirical distribution
ν =
n
X
j=1
q
j
δ
z
j
onto the
m
-categorical representation (Definition 5.12). For
i
= 1
, . . . , m
,
Equation 5.24 becomes
p
i
=
n
X
j=1
q
j
h
i
ς
−1
m
(z
j
−θ
i
)
,
which can be implemented in linear time with two for loops (as was done in
Algorithm 3.4).
Similarly, the projection of
ν
onto the
m
-quantile representation (Defini-
tion 5.11) is achieved by sorting the locations
z
i
to construct the cumulative
distribution function from their associated probabilities q
i
:
F
ν
(z) =
n
X
j=1
q
j {z
j
≤z}
,
from which quantile midpoints can be extracted.
Because the categorical-Cramér and quantile-
w
1
pairs recur so often through-
out this book, it is convenient to give a name to the algorithms that iteratively
apply their respective projected operators. We call these algorithms categorical
Draft version.

Distributional Dynamic Programming 137
Algorithm 5.3: Categorical dynamic programming
Algorithm parameters: representation parameters θ
1
, . . . , θ
m
, m,
initial probabilities
(p
i
(x))
m
i=1
: x ∈X
,
desired number of iterations K
for k = 1, . . . , K do
η(x) =
m
P
i=1
p
i
(x)δ
θ
i
for x ∈X
z
0
j
(x), p
0
j
(x)
m(x)
j=1
: x ∈X
←T
π
η Algorithm 5.1
foreach state x ∈X do
for i = 1, …, m do
p
i
(x) ←
m(x)
P
j=1
p
0
j
(x)h
i
ς
−1
m
(z
0
j
−θ
i
)
end for
end foreach
end for
return
(p
i
(x))
m
i=1
: x ∈X)
and quantile dynamic programming, respectively (CDP and QDP; Algorithms
5.3 and 5.4).
43
For both categorical and quantile dynamic programming, the computational
cost is dominated by the number of particles produced by the distributional
Bellman operator, prior to projection. Since the number of particles in the
representation is a constant
m
, we have that per state, there may be up to
N
=
mN
R
N
X
particles in this intermediate step. Thus, the cost of
K
iterations
with the
m
-categorical representation is
O
(
KmN
R
N
2
X
), not too dissimilar to the
cost of performing iterative policy evaluation with value functions. Due to the
sorting operation, the cost of
K
iterations with the
m
-quantile representation is
larger, at
O
KmN
R
N
2
X
log
(
mN
R
N
X
)
. In Chapter 6, we describe an incremental
algorithm that avoids the explicit sorting operation and is in some cases more
computationally efficient.
In designing distributional dynamic programming algorithms, there is a good
deal of flexibility in the choice of representation and in the projection step once
a representation has been selected. There are basic properties we would like
43.
To be fully accurate, we should call these the categorical-Cramér and quantile-
w
1
dynamic
programming algorithms, given that they combine particular choices of probability representation
and projection. However, brevity has its virtues.
Draft version.

138 Chapter 5
Algorithm 5.4: Quantile dynamic programming
Algorithm parameters: initial locations
(θ
i
(x))
m
i=1
: x ∈X),
desired number of iterations K
for k = 1, . . . , K do
η(x) =
m
P
i=1
1
m
δ
θ
i
(x)
for x ∈X
η
0
=
z
0
j
(x), p
0
j
(x)
m(x)
j=1
: x ∈X
←T
π
η Algorithm 5.1
foreach state x ∈X do
(z
0
j
(x), p
0
j
(x))
m(x)
i=1
←sort ((z
0
j
(x), p
0
j
(x))
m(x)
i=1
)
for j = 1, …, m do
P
j
(x) ←
j
P
i=1
p
0
i
(x)
end for
for i = 1, …, m do
j ←min{l : P
l
(x) ≥τ
i
}
θ
i
(x) ←z
0
j
(x)
end for
end foreach
end for
return
(θ
i
(x))
m
i=1
: x ∈X
from the sequence defined by Equation 5.27, such as a guarantee of convergence,
and further a limit that does not depend on our choice of initialization. Certain
combinations of representation and projection will ensure these properties hold,
as we explore in Section 5.9, while others may lead to very poorly behaved
algorithms (see Exercise 5.19). In addition, using a representation and projection
also necessarily incurs some approximation error relative to the true return
function. It is often possible to obtain quantitative bounds on this approximation
error, as Section 5.10 describes, but often judgment must be used as to what
qualitative types of approximation are the most acceptable for task in hand; we
return to this point in Section 5.11.
5.8 Error Due to Diffusion
In Section 5.4, we showed that the distributional algorithm for the normal
representation finds the best fit to the return function
η
π
, as measured in
Kullback–Leibler divergence. Implicit in our derivation was the fact that we
Draft version.
Distributional Dynamic Programming 139
η
0
η
1
··· η
k
ˆη
0
ˆη
1
··· ˆη
k
T
π
Π
F
T
π
Π
F
T
π
Π
F
Π
F
T
π
Π
F
T
π
Π
F
T
π
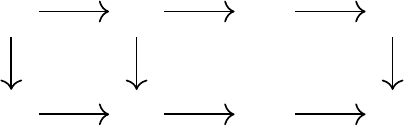
Figure 5.5
A diffusion-free projection operator Π
F
yields a distributional dynamic program-
ming procedure that is equivalent to first computing an exact return function and then
projecting it.
could interleave projection and update steps to obtain the same solution as if
we had first determined
η
π
without approximation and then found its best fit in
F
N
. We call a projection operator with this property diffusion-free (Figure 5.5).
Definition 5.18.
Consider a representation
F
and a projection operator Π
F
for that representation. The projection operator Π
F
is said to be diffusion-free
if, for any return function η ∈F
X
, we have
Π
F
T
π
Π
F
η = Π
F
T
π
η .
As a consequence, for any
k ≥
0 and any
η ∈F
X
, a diffusion-free projection
operator satisfies
(Π
F
T
π
)
k
η = Π
F
(T
π
)
k
η . 4
Algorithms that implement diffusion-free projection operators are quite
appealing, because they behave as if no approximation had been made until the
final iteration. Unfortunately, such algorithms are the exception, rather than the
rule. By contrast, without this guarantee, an algorithm may accumulate excess
error from iteration to iteration – we say that the iterates
η
0
, η
1
, η
2
, . . .
undergo
diffusion. Known projection algorithms for
m
-particle representations suffer
from this issue, as the following example illustrates.
Example 5.19.
Consider a chain of
n
states with a deterministic left-to-right
transition function (Figure 5.6). The last state of this chain, x
n
, is terminal and
produces a reward of 1; all other states yield no reward. For
t ≥
0, the discounted
return at state
x
n−t
is deterministic and has value
γ
t
; let us denote its distribution
by
η
(
x
n−t
). If we approximate this distribution with
m
= 11 particles uniformly
spaced from 0 to 1, the best categorical approximation assigns probability to
the two particles closest to γ
t
.
If we instead use categorical dynamic programming, we find a different
solution. Because each iteration of the projected Bellman operator must produce
Draft version.

140 Chapter 5
x
1
x
3
x
5
x
7
x
9
State
Return
m-Categorical
Approximation
0.0
0.2
0.4
0.6
0.8
1.0
x
1
x
3
x
5
x
7
x
9
State
Return
Categorical
Dynamic Programming
0.0
0.2
0.4
0.6
0.8
1.0
(a)
(b) (c)
Figure 5.6
(a)
An
n
-state chain with a single nonzero reward at the end.
(b)
The (
2
, F
C,m
)-optimal
approximation to the return function, for
n
= 10,
m
= 11, and
θ
1
= 0
, . . . , θ
11
= 1. The
probabilities assigned to each location are indicated in grayscale (white = 0, black =
1).
(c)
The approximation found by categorical dynamic programming with the same
representation.
a categorical distribution, the iterates undergo diffusion. Far from the terminal
state, the return distribution found by Algorithm 5.2 is distributed on a much
larger support than the best categorical approximation of η(x
i
). 4
The diffusion in Example 5.19 can be explained analytically. Let us asso-
ciate each particle with an integer
j
= 0
, . . . ,
10, corresponding to the location
j
10
. For concreteness, let
γ
= 1
−ε
for some 0
< ε
0
.
1, and consider the
return-distribution function obtained after
N
iterations of categorical dynamic
programming:
ˆη = (Π
c
T
π
)
n
η
0
.
Because there are no cycles, one can show that further iterations leave the
approximation unchanged.
If we interpret the
m
particle locations as states in a Markov chain, then we
can view the return distribution
ˆη
(
x
n−t
) as the probability distribution of this
Markov chain after
t
time steps (
t ∈{
0
, . . . , n −
1
}
). The transition function for
states j = 1 . . . 10 is
P(bγ jc | j) = dγ je−γ j
P(dγ je | j) = 1 −dγ je+ γ j .
For
j
= 0, we simply have
P
(0
|
0) = 1 (i.e., state 0 is terminal). When
γ
is
sufficiently small compared to the gap
ς
m
= 0
.
1 between neighboring particle
Draft version.

Distributional Dynamic Programming 141
locations, the process can be approximated with a binomial distribution:
ˆ
G(x
n−t
) ∼1 −t
−1
Binom(1 −γ, t) ,
where
ˆ
G
is the return-variable function associated with
ˆη
. Figure 5.6c gives a
rough illustration of this point, with a bell-shaped distribution emerging in the
return distribution at state x
1
.
5.9 Convergence of Distributional Dynamic Programming
We now use the theory of operators developed in Chapter 4 to characterize the
behavior of distributional dynamic programming in the policy evaluation setting:
its convergence rate, its point of convergence, and also the approximation error
incurred. Specifically, this theory allows us to measure how these quantities
are impacted by different choices of representation and projection. Although
the algorithmic discussion in previous sections has focused on implementa-
tions of distributional dynamic programming in the case of finitely supported
reward distributions, the results presented here apply without this assumption
(see Exercise 5.9 for indications of how distributional dynamic programming
algorithms may be implemented in such cases). As we will see in Chapter 6,
the theory developed here also informs incremental algorithms for learning the
return-distribution function.
Let us consider a probability metric
d
, possibly different from the metric
under which the projection is performed (when applicable), and which we call
the analysis metric. We use the analysis metric to characterize instances of
Algorithm 5.2 in terms of the Lipschitz constant of the projected operator.
Definition 5.20.
Let (
M, d
) be a metric space, and let
O
:
M → M
be a function
on this space. The Lipschitz constant of O under the metric d is
kOk
d
= sup
U,U
0
∈M
U,U
0
d(OU, OU
0
)
d(U, U
0
)
. 4
When
O
is a contraction mapping, its Lipschitz constant is simply its con-
traction modulus. That is, under the conditions of Theorem 4.25 applied to a
c-homogeneous d, we have
kT
π
k
d
≤γ
c
.
Definition 5.20 extends the notion of a contraction modulus to operators, such
as projections, that are not contraction mappings.
Lemma 5.21.
Let (
M, d
) be a metric space, and let
O
1
, O
2
:
M → M
be func-
tions on this space. Write
O
1
O
2
for the composition of these mappings.
Then,
kO
1
O
2
k
d
≤kO
1
k
d
kO
2
k
d
. 4
Draft version.

142 Chapter 5
Proof. By applying the definition of the Lipschitz constant twice, we have
d(O
1
O
2
U, O
1
O
2
U
0
) ≤kO
1
k
d
d(O
2
U, O
2
U
0
) ≤kO
1
k
d
kO
2
k
d
d(U, U
0
) ,
as required.
Lemma 5.21 gives a template for validating and understanding different
instantiations of Algorithm 5.2. Here, we consider the metric space defined by
the finite domain of our analysis metric, (
P
d
(
R
)
X
, d
), and use Lemma 5.21 to
characterize Π
F
T
π
in terms of the Lipschitz constants of its parts (Π
F
and
T
π
). By analogy with the conditions of Proposition 4.27, where needed, we
will assume that the environment (more specifically, its random quantities) is
reasonably behaved under d.
Assumption 5.22(d).
The finite domain
P
d
(
R
)
X
is closed under both the
projection Π
F
and the Bellman operator T
π
, in the sense that
η ∈P
d
(R)
X
=⇒ T
π
η, Π
F
η ∈P
d
(R)
X
. 4
Assumption 5.22(
d
) guarantees that distributions produced by the distri-
butional Bellman operator and the projection have finite distances from one
another. For many choices of
d
of interest, Assumption 5.22 can be easily shown
to hold when the reward distributions are bounded; contrast with Proposition
4.16.
The Lipschitz constant of projection operators must be at least 1, since for
any ν ∈F ,
Π
F
ν = ν .
In the case of the Cramér distance
2
, we can show that it behaves much like a
Euclidean metric, from which we obtain the following result on
2
projections.
Lemma 5.23.
Consider a representation
F ⊆P
2
(
R
). If
F
is complete with
respect to
2
and convex, then the
2
-projection Π
F ,
2
:
P
2
(
R
)
→F
is a
nonexpansion in that metric:
kΠ
F ,
2
k
2
= 1 .
Furthermore, the result extends to return functions and the supremum extension
of
2
:
kΠ
F ,
2
k
2
= 1 . 4
The proof is given in Remark 5.6. Exercise 5.15 asks you show that the
m
-categorical representation is convex and complete with respect to the Cramér
distance. From this, we immediately derive the following.
Lemma 5.24.
The projected distributional Bellman operator instantiated with
F
=
F
C,m
and
d
=
2
has contraction modulus
γ
1
/2
with respect to
2
on the
Draft version.
Distributional Dynamic Programming 143
space P
2
(R)
X
. That is,
kΠ
c
T
π
k
2
≤γ
1
/2
. 4
Lemma 5.24 gives a formal reason for why the use of the
m
-categorical
representation, coupled with a projection based on triangular kernel, produces a
convergent distributional dynamic programming algorithm.
The
m
-quantile representation, however, is not convex. This precludes a direct
appeal to an argument based on a quantile analogue to Lemma 5.23. Nor is
the issue simply analytical: the
w
1
Lipschitz constant of the projected Bellman
operator Π
q
T
π
is greater than 1 (see Exercise 5.16). Instead, we need to use the
∞
-Wasserstein distance as our analysis metric. As the
w
1
-projection onto
F
Q,m
is a nonexpansion in w
∞
, we obtain the following result.
Lemma 5.25.
Under Assumption 5.22(
w
∞
), the projected distributional Bell-
man operator Π
q
T
π
:
P
∞
(
R
)
X
→P
∞
(
R
)
X
has contraction modulus
γ
in
w
∞
.
That is,
kΠ
q
T
π
k
w
∞
≤γ . 4
Proof.
Since
T
π
is a
γ
-contraction in
w
∞
by Proposition 4.15, it is sufficient
to prove that Π
q
:
P
∞
(
R
)
→P
∞
(
R
) is a nonexpansion in
w
∞
; the result then
follows from Lemma 5.21. Given two distributions ν
1
, ν
2
∈P
∞
(R), we have
w
∞
(ν
1
, ν
2
) = sup
τ∈(0,1)
|F
−1
ν
1
(τ) −F
−1
ν
2
(τ)|.
Now note that
Π
q
ν
1
=
1
m
m
X
i=1
δ
F
−1
ν
1
(τ
i
)
, Π
q
ν
2
=
1
m
m
X
i=1
δ
F
−1
ν
2
(τ
i
)
,
where τ
i
=
2i−1
2m
. We have
w
∞
(Π
q
ν
1
, Π
q
ν
2
) = max
i=1,…,m
F
−1
ν
1
(τ
i
) −F
−1
ν
2
(τ
i
)
≤ sup
τ∈(0,1)
F
−1
ν
1
(τ) −F
−1
ν
2
(τ)
= w
∞
(ν
1
, ν
2
) ,
as required.
The derivation of a contraction modulus for a projected Bellman operator
provides us with two results. By Proposition 4.7, it establishes that if Π
F
T
π
has a fixed point
ˆη
, then Algorithm 5.2 converges to this fixed point. Second, it
also establishes the existence of such a fixed point when the representation is
complete with respect to the analysis metric
d
, based on Banach’s fixed point
theorem; a proof is provided in Remark 5.7.
Draft version.

144 Chapter 5
Theorem 5.26
(Banach’s fixed point theorem)
.
Let (
M, d
) be a complete
metric space and let
O
be a contraction mapping on
M
, with respect to
d
.
Then O has a unique fixed point U
∗
∈ M. 4
Proposition 5.27.
Let
d
be a
c
-homogeneous, regular probability metric
that is
p
-convex for some
p ∈
[1
, ∞
) and let
F
be a representation complete
with respect to
d
. Consider Algorithm 5.2 instantiated with a projection
step described by the operator Π
F
, and suppose that Assumption 5.22(
d
)
holds. If Π
F
is a nonexpansion in
d
, then the corresponding projected
Bellman operator Π
F
T
π
has a unique fixed point
ˆη
π
in
P
d
(
R
)
X
satisfying
ˆη
π
= Π
F
T
π
ˆη
π
.
Additionally, for any ε > 0, if K the number of iterations is such that
K ≥
log
1
ε
+ log d(η
0
, ˆη
π
)
c log
1
γ
with
η
0
(
x
)
∈P
d
(
R
) for all
x
, then the output
η
K
of Algorithm 5.2 satisfies
d(η
K
, ˆη
π
) ≤ε . 4
Proof.
By the assumptions in the statement, we have that
T
π
is a
γ
c
-contraction
on
P
d
(
R
)
X
by Theorem 4.25, and by Lemma 5.21, Π
F
T
π
is a
γ
c
-contraction
on
P
d
(
R
)
X
. By Banach’s fixed point theorem, there is a unique fixed point
ˆη
π
for Π
F
T
π
in P
d
(R)
X
. Now note
d(η
K
, ˆη
π
) = d(Π
F
T
π
η
K−1
, Π
F
T
π
ˆη
π
) ≤γ
c
d(η
K−1
, ˆη
π
) ,
so by induction
d(η
K
, ˆη
π
) ≤γ
cK
d(η
0
, ˆη
π
) .
Setting the right-hand side to less than
ε
and rearranging yields the result.
Although Proposition 5.27 does not allow us to conclude that a particular
algorithm will fail, it cautions us against projections in certain probability
metrics. For example, because the distributional Bellman operator is only a non-
expansion in the supremum total variation distance, we cannot guarantee a good
approximation with respect to this metric after any finite number of iterations.
Because we would like the projection step to be computationally efficient, this
argument also gives us a criterion with which to choose a representation. For
example, although the
m
-particle representation is clearly more flexible than
Draft version.

Distributional Dynamic Programming 145
either the categorical or quantile representations, it is currently not known how
to efficiently and usefully project onto it.
5.10 Quality of the Distributional Approximation
Having identified conditions under which the iterates produced by distributional
dynamic programming converge, we now ask: to what do they converge? We
answer this question by measuring how close the fixed point
ˆη
π
of the projected
Bellman operator (computed by Algorithm 5.2 in the limit of the number of
iterations) is to the true return function
η
π
. The quality of this approximation
depends on a number of factors: the choice and size of representation
F
, which
determines the optimal approximation of
η
π
within
F
, as well as properties of
the projection step.
Proposition 5.28.
Let
d
be a
c
-homogeneous, regular probability metric
that is
p
-convex for some
p ∈
[1
, ∞
), and let
F ⊆P
d
(
R
) be a representation
complete with respect to
d
. Let Π
F
be a projection operator that is a
nonexpansion in
d
, and suppose Assumption 5.22(
d
) holds. Consider the
projected Bellman operator Π
F
T
π
with fixed point ˆη
π
∈P
d
(R)
X
. Then,
d(ˆη
π
, η
π
) ≤
d(Π
F
η
π
, η
π
)
1 −γ
c
.
When Π
F
is a
d
-projection in some probability metric
d
, Π
F
η
π
is a
(d, F )-optimal approximation of the return function η
π
. 4
Proof. We have
d(η
π
, ˆη
π
) ≤d(η
π
, Π
F
η
π
) + d(Π
F
η
π
, ˆη
π
)
= d (η
π
, Π
F
η
π
) + d(Π
F
T
π
η
π
, Π
F
T
π
ˆη
π
)
≤d (η
π
, Π
F
η
π
) + γ
c
d(η
π
, ˆη
π
) .
Rearranging then gives the result.
From this, we immediately derive a result regarding the fixed point
ˆη
π
c
of the
projected operator Π
c
T
π
.
Corollary 5.29.
The fixed point
ˆη
π
c
of the categorical-projected Bellman
operator Π
c
T
π
: P
1
(R) →P
1
(R) satisfies
2
(ˆη
π
c
, η
π
) ≤
2
(Π
c
η
π
, η
π
)
1 −γ
1
/2
.
Draft version.

146 Chapter 5
Figure 5.7
The return-distribution function estimates obtained by applying categorical dynamic
programming to the Cliffs domain (Example 2.9; here, with the safe policy). Each panel
corresponds to a different number of particles.
If the return distributions (
η
π
(
x
) :
x ∈X
) are supported on [
θ
1
, θ
m
], we further
have that, for each x ∈X,
min
ν∈F
C,m
2
2
(ν, η
π
(x)) ≤ς
m
m
X
i=1
F
η
π
(x)
θ
1
+ iς
m
−F
η
π
(x)
θ
1
+ (i −1)ς
m
2
≤ς
m
,
(5.28)
and hence
2
(ˆη
π
c
, η
π
) ≤
1
1 −γ
1
/2
θ
m
−θ
1
m −1
. 4
Proposition 5.28 suggests that the excess error may be greater when the
projection is performed in a metric for which
c
is small. In the particular case of
the Cramér distance, the constant in Corollary 5.29 can in fact be strengthened
to
1
√
1−γ
by arguing about the geometry of the probability space under
2
under certain conditions; see Remark 5.6 for a discussion of this geometry and
Rowland et al. (2018) for details on the strengthened bound.
Varying the number of particles in the categorical representation allows the
user to control both the complexity of the associated dynamic programming
algorithm and the error of the fixed point
ˆη
π
c
(Figure 5.7). As discussed in the
first part of this chapter, both the memory and time complexity of computing
with this representation increase with
m
. On the other hand, Corollary 5.29
establishes that increasing
m
also reduces the approximation error incurred from
dynamic programming.
Proposition 5.28 can be similarly used to analyze quantile dynamic pro-
gramming. This result, under the conditions of Lemma 5.25, shows that the
fixed point
ˆη
π
q
of the projected operator Π
q
T
π
for the
m
-quantile representation
satisfies
w
∞
(ˆη
π
q
, η
π
) ≤
w
∞
(Π
q
η
π
, η
π
)
1 −γ
.
Draft version.

Distributional Dynamic Programming 147
Unfortunately, the distance
w
∞
(Π
q
η
π
, η
π
) does not necessarily vanish as the
number of particles
m
in the quantile representation increases. This is because
w
∞
is in some sense a very strict distance (Exercise 5.18 makes this point
precise). Nevertheless, the dynamic programming algorithm associated with the
quantile representation enjoys a similar trade-off between complexity and accu-
racy as established for the categorical algorithm above. This can be shown by
instead analyzing the algorithm via the more lenient
w
1
distance; Exercise 5.20
provides a guide to a proof of this result.
Lemma 5.30.
Suppose that for each (
x, a
)
∈X×A
, the reward distribution
P
R
(
· | x, a
) is supported on the interval [
R
min
, R
max
]. Then the
m
-quantile fixed
point ˆη
π
q
satisfies
w
1
(ˆη
π
q
, η
π
) ≤
3(V
max
−V
min
)
2m(1 −γ)
.
In addition, consider an initial return function
η
0
with distributions with support
bounded in [V
min
, V
max
] and the iterates
η
k+1
= Π
q
T
π
η
k
produced by quantile dynamic programming. Then we have, for all k ≥0,
w
1
(η
k
, η
π
) ≤γ
k
(V
max
−V
min
) +
3(V
max
−V
min
)
2m(1 −γ)
. 4
5.11 Designing Distributional Dynamic Programming Algorithms
Although both categorical and quantile dynamic programming algorithms arise
from natural choices, there is no reason to believe that they lead to the best
approximation of the return-distribution function for a fixed number of parame-
ters. For example, can the error be reduced by using a
m
2
-particle representation
instead? Are there measurable characteristics of the environment that could
guide the choice of distribution representation?
As a guide to further investigations, Table 5.1 summarizes the desirable
properties of representations and projections that were studied in this chapter,
as they pertain to the design of distributional dynamic programming algorithms.
Because these properties arise from the combination of a representation with
a particular projection, every such combination is likely to exhibit a different
set of properties. This highlights how new DDP algorithms with desirable
characteristics may be produced by simply trying out different combinations.
Because these properties arise from the combination of a representation with
a particular projection, one can naturally expect new algorithms for example,
one can imagine a new algorithm based on the quantile representation that is a
nonexpansion in the 1- or 2-Wasserstein distances.
Draft version.
148 Chapter 5
Included in this table is whether a representation is mean-preserving. We say
that a representation
F
and its associated projection operator Π
F
are mean-
preserving if for any distribution
ν
from a suitable space, the mean of Π
F
ν
is
the same as that of
ν
. The
m
-categorical algorithm presented in this chapter is
mean-preserving provided the range of considered returns does not exceed the
boundaries of its support; the
m
-quantile algorithm is not. In addition to the
mean, we can also consider what happens to other aspects of the approximated
distributions. For example, the
m
-categorical algorithm produces probability
distributions that in general have more variance than those of the true return
function.
The choice of representation also has consequences beyond distributional
dynamic programming. In the next chapter, for example, we will consider the
design of incremental algorithms for learning return-distribution functions from
samples. There, we will see that the projected operator derived from the cate-
gorical representation directly translates into an incremental algorithm, while
the operator derived from the quantile representation does not. In Chapter 9,
we will also see how the choice of representation interplays with the use of
parameterized models such as neural networks to represent the return function
compactly. Another consideration, not listed here, concerns the sensitivity of the
algorithm to its parameters: for example, for small values of
m
, the
m
-quantile
representation tends to be a better choice than the
m
-categorical representation,
which suffers from large gaps between its particles’ locations (as an extreme
example, take m = 2).
The design and study of representations remains an active topic in distribu-
tional reinforcement learning. The representations we presented here are by no
mean an exhaustive portrait of the field. For example, Barth-Maron et al. (2018)
considered using mixtures of
m
normal distributions in domains with vector-
valued action spaces. Analyzing representations like these is more challenging
because known projection methods suffer from local minima, which in turn
implies that dynamic programming may give different (and possibly suboptimal)
solutions for different initial conditions.
5.12 Technical Remarks
Remark 5.1
(
Finiteness of R
)
.
In the algorithms presented in this chapter, we
assumed that rewards are distributed on a finite set
R
. This is not actually needed
for most of our analysis but makes it possible to compute expectations and
convolutions in finite time and hence devise concrete dynamic programming
algorithms. However, there are many problems in which the rewards are better
modeled using continuous or unbounded distributions. Rewards generated from
Draft version.

Distributional Dynamic Programming 149
T
π
-closed Tractable Expressive Diffusion-
free
Mean-
preserving
Empirical DP X X X X
Normal DP X X X
Categorical DP X X *
Quantile DP X X
Table 5.1
Desirable characteristics of distributional dynamic programming algorithms. “Empirical
DP” and “Normal DP” refer to distributional dynamic programming with the empir-
ical and normal distributions, respectively (Sections 5.3 and 5.4). While no known
representation–projection pair satisfies all of these, the categorical-Cramér and quantile-
w
1
choices offer a good compromise.
*
The categorical representation is mean-preserving
provided its support spans the range of possible returns.
observations of a physical process are often well modeled by a normal distri-
bution to account for sensor noise. Rewards derived from a queuing process,
such as the number of customers who make a purchase at an ice cream shop in
a give time interval, can be modeled by a Poisson distribution. 4
Remark 5.2
(
NP-hardness of computing return distributions
)
.
Recall that
a problem is said to be NP-hard if its solution can also be used to solve all
problems in the class NP, by means of a polynomial-time reduction (Cormen
et al. 2001). This remark illustrates how the problem of computing certain
aspects of the return-distribution function for a given Markov decision process
is NP-hard, by reduction from one of Karp’s original NP-complete problems,
the Hamiltonian cycle problem. Reductions from the Hamiltonian cycle problem
have previously been used to prove the NP-hardness of a variety of problems
relating to constrained Markov decision processes (Feinberg 2000).
Let
G
= (
V, E
) be a graph, with
V
=
{
1
, . . . , n}
for some
n ∈N
+
. The Hamilto-
nian cycle problem asks whether there is a permutation of vertices
σ
:
V →V
such that
{σ
(
i
)
, σ
(
i
+ 1)
}∈E
for each
i ∈
[
n −
1], and
{σ
(
n
)
, σ
(1)
}∈E
. Now con-
sider an MDP whose state space is the set of integers from 1 to
n
, denoted
X
=
{
1
, . . . , n}
, and with a singleton action set
A
=
{a}
, a transition kernel that
encodes a random walk over the graph
G
, and a uniform initial state distribution
ξ
0
. Further, specify reward distributions as
P
R
(
· | x, a
) =
δ
x
for each
x ∈X
, and
set
γ <
1
/n+2
. For such a discount factor, there is a one-to-one mapping between
Draft version.

150 Chapter 5
trajectories and returns. As the action set is a singleton, there is a single policy
π
.
It can be shown that there is a Hamiltonian cycle in
G
if and only if the support
of the return distribution has nonempty intersection with the set
[
σ∈S
n
n−1
X
t=0
γ
t
σ(t + 1) + γ
n
σ(1),
n−1
X
t=0
γ
t
σ(t + 1) + γ
n
(σ(1) + 1)
. (5.29)
Since the MDP description is clearly computable in polynomial time from the
graph specifying the Hamiltonian cycle problem, it must therefore be the case
that ascertaining whether the set in Expression 5.29 has nonempty intersec-
tion with the return distribution support is NP-hard. The full proof is left as
Exercise 5.21. 4
Remark 5.3
(
Existence of d-projections
)
.
As an example of a setting where
d
-projections do not exist, let
θ
1
, …, θ
m
∈R
and consider the softmax categorical
representation
F =
n
m
X
i=1
e
ϕ
i
P
m
j=1
e
ϕ
j
δ
θ
i
: ϕ
1
, …, ϕ
m
∈R
o
.
For the distribution
δ
θ
1
and metric
d
=
w
2
, there is no optimal (
F , d
)-
approximation to
δ
θ
1
, since for any distribution in
F
, there is another
distribution in
F
that lies closer to
δ
θ
1
with respect to
w
2
. The issue is that there
are elements of the representation which are arbitrarily close to the distribution
to be projected, but there is no distribution in the representation that dominates
all others as in Equation 5.23. An example of a sufficient condition for the
existence of an optimal (
F , d
)-approximation to
ˆν ∈P
d
(
R
) is that the metric
space (
F , d
) has the Bolzano–Weierstrass property, also known as sequential
compactness: for any sequence (
ν
k
)
k≥0
in
F
, there is subsequence that con-
verges to a point in
F
with respect to
d
. When this assumption holds, we may
take the sequence (ν
k
)
k≥0
in F to satisfy
d(ν
k
, ˆν) ≤ inf
ν∈F
d(ν, ˆν) +
1
k + 1
.
Using the Bolzano–Weierstrass property, we may pass to a subsequence (
ν
k
n
)
n≥0
converging to ν
∗
∈F . We then observe
d(ν
∗
, ˆν) ≤d(ν
∗
, ν
k
n
) + d(ν
k
n
, ˆν) → inf
ν∈F
d(ν, ˆν) ,
showing that
ν
∗
is an optimal (
F , d
)-approximation to
ˆν
. The softmax repre-
sentation (under the
w
2
metric) fails to have the Bolzano–Weierstrass property.
As an example, the sequence of distributions (
k
k+1
δ
θ
1
+
1
k+1
δ
θ
2
)
k≥0
in
F
has no
subsequence that converges to a point in F . 4
Draft version.

Distributional Dynamic Programming 151
Remark 5.4
(
Proof of Proposition 5.14
)
.
We will demonstrate the following
Pythagorean identity. For any ν ∈P
2
(R), and ν
0
∈F
C,m
, we have
2
2
(ν, ν
0
) =
2
2
(ν, Π
c
ν) +
2
2
(Π
c
ν, ν
0
) .
From this, it follows that
ν
0
= Π
c
ν
is the unique
2
-projection of
ν
onto
F
C,m
,
since this choice of
ν
0
uniquely minimizes the right-hand side. To show this
identity, we first establish an interpretation of the cumulative distribution func-
tion (CDF) of Π
c
ν
as averaging the CDF values of
ν
on each interval (
θ
i
, θ
i+1
)
for i = 1, …, m −1. First note that for z ∈(θ
i
, θ
i+1
], we have
h
i
ς
−1
m
(z −θ
i
)
= 1 −ς
−1
m
|z −θ
i
|
=
1
θ
i+1
−θ
i
θ
i+1
−θ
i
+ θ
i
−z
=
θ
i+1
−z
θ
i+1
−θ
i
.
Now, for i = 1, …, m −1, we have
F
Π
c
ν
(θ
i
) =
i
X
j=1
E
Z∼ν
[h
j
(Z)]
= E
Z∼ν
h
{Z ≤θ
i
}+ {Z ∈(θ
i
, θ
i+1
]}
θ
i+1
−Z
θ
i+1
−θ
i
i
=
1
θ
i+1
−θ
i
Z
θ
i+1
θ
i
F
ν
(z)dz .
Now note
2
2
(ν, ν
0
) =
Z
∞
−∞
(F
ν
(z) −F
ν
0
(z))
2
dz
(a)
=
Z
∞
−∞
(F
ν
(z) −F
Π
c
ν
(z))
2
dz +
Z
∞
−∞
(F
Π
c
ν
(z) −F
ν
0
(z))
2
dz
+ 2
Z
∞
−∞
(F
ν
(z) −F
Π
c
ν
(z))(F
Π
c
ν
(z) −F
ν
0
(z))dz
=
2
2
(ν, Π
c
ν) +
2
2
(Π
c
ν, ν
0
)
+ 2
Z
θ
1
−∞
+
m−1
X
i=1
Z
θ
i+1
θ
i
+
Z
∞
θ
m
(F
ν
(z) −F
Π
c
ν
(z))(F
Π
c
ν
(z) −F
ν
0
(z))dz
(b)
=
2
2
(ν, Π
c
ν) +
2
2
(Π
c
ν, ν
0
)
establishing the identity as required. Here, (a) follows by adding and subtracting
F
Π
c
ν
inside the parentheses and expanding, and (b) follows by noting that on
(
−∞, θ
1
) and (
θ
m
, ∞
),
F
Π
c
ν
=
F
v
0
, and on each interval (
θ
i
, θ
i+1
),
F
Π
c
ν
−F
v
0
is
Draft version.

152 Chapter 5
constant and
F
Π
c
ν
is constant and equals the average of
F
ν
on the interval,
meaning that
Z
θ
i+1
θ
i
(F
ν
(z) −F
Π
c
ν
(z))(F
Π
c
ν
(z) −F
ν
0
(z))dz
= (F
Π
c
ν
(θ
i
) −F
ν
0
(θ
i
))
Z
θ
i+1
θ
i
(F
ν
(z) −F
Π
c
ν
(z))dz = 0 ,
as required. 4
Remark 5.5
(
Proof of Lemma 5.16
)
.
Assume that
F
−1
ν
is continuous at
τ
∗
=
a+b
2
; this is not necessary but simplifies the proof. For any τ,
F
−1
ν
(τ) −θ
(5.30)
is a convex function, and hence so is Equation 5.26. A subgradient
44
for
Equation 5.30 is
g
τ
(θ) =
1 if θ < F
−1
ν
(τ)
−1 if θ > F
−1
ν
(τ)
0 if θ = F
−1
ν
(τ) .
A subgradient for Equation 5.26 is therefore
g
[a,b]
(θ) =
Z
b
τ=a
g
τ
(θ)dτ
=
Z
F
ν
(θ)
τ=a
−1 dτ +
Z
b
τ=F
ν
(θ)
1 dτ
= −(F
ν
(θ) −a) + (b −F
ν
(θ)).
Setting the subgradient to zero and solving for θ,
0 = a + b −2F
ν
(θ)
=⇒ F
ν
(θ) =
a + b
2
=⇒ θ = F
−1
ν
a + b
2
!
. 4
Remark 5.6
(
Proof of Lemma 5.23
)
.
The argument follows the standard proof
that finite-dimensional Euclidean projections onto closed convex sets are non-
expansions. Throughout, we write Π for Π
F ,
2
for conciseness. We begin with
44.
For a convex function
f
:
R →R
, we say that
g
:
R →R
is a subgradient for
f
if for all
z
1
, z
2
∈R
,
we have f (z
2
) ≥ f (z
1
) + g(z
1
)(z
2
−z
1
).
Draft version.
Distributional Dynamic Programming 153
the observation that for any ν ∈P
2
(R) and ν
0
∈F , we have
Z
R
(F
ν
(z) −F
Πν
(z))(F
ν
0
(z) −F
Πν
(z))dz ≤0 , (5.31)
since if not, we have (1 −ε)Πν + εν
0
∈F for all ε ∈(0, 1) by convexity, and
2
2
(ν, (1 −ε)Πν + εν
0
)
=
Z
R
(F
ν
(z) −(1 −ε)F
Πν
(z) −εF
ν
0
(z))
2
dz
=
2
2
(ν, Πν) −2ε
Z
R
(F
ν
(z) −F
Πν
(z))(F
ν
0
(z) −F
Πν
(z))dz + O(ε
2
) .
This final line must be at least as great as
2
2
(
ν,
Π
ν
) for all
ε ∈
(0
,
1), by definition
of Π. It must therefore be the case that Inequality 5.31 holds, since if not, we
could select
ε >
0 sufficiently small to make
2
2
(
ν,
(1
−ε
)Π
ν
+
εν
0
) smaller than
2
2
(ν, Πν).
Now take ν
1
, ν
2
∈P
2
(R). Applying the above inequality twice yields
Z
R
(F
ν
1
(z) −F
Πν
1
(z))(F
Πν
2
(z) −F
Πν
1
(z))dz ≤0 ,
Z
R
(F
ν
2
(z) −F
Πν
2
(z))(F
Πν
1
(z) −F
Πν
2
(z))dz ≤0 .
Adding these inequalities then yields
Z
R
(F
ν
1
(z) −F
ν
2
(z) + F
Πν
1
(z) −F
Πν
2
(z))(F
Πν
1
(z) −F
Πν
2
(z))dz ≤0
=⇒
2
2
(Πν
1
, Πν
2
) +
Z
R
(F
ν
1
(z) −F
ν
2
(z))(F
Πν
1
(z) −F
Πν
2
(z))dz ≤0
=⇒
2
2
(Πν
1
, Πν
2
) ≤
Z
R
(F
ν
2
(z) −F
ν
1
(z))(F
Πν
1
(z) −F
Πν
2
(z))dz .
Applying the Cauchy–Schwarz inequality to the remaining integral then yields
2
2
(Πν
1
, Πν
2
) ≤
2
(Πν
1
, Πν
2
)
2
(ν
1
, ν
2
) ,
from which the result follows by rearranging. 4
Remark 5.7
(
Proof of Banach’s fixed point theorem (Theorem 5.26)
)
.
The
map
O
has at most one fixed point by Proposition 4.5. It therefore suffices to
exhibit a fixed point in
M
. Let
β ∈
[0
,
1) be the contraction modulus of
O
, and
let
U
0
∈ M
. Consider the sequence (
U
k
)
k≥0
defined by
U
k+1
=
OU
k
for
k ≥
0. For
any l > k, we have
d(U
l
, U
k
) ≤β
k
d(U
l−k
, U
0
)
Draft version.

154 Chapter 5
≤β
k
l−k−1
X
j=0
d(U
j
, U
j+1
)
≤β
k
l−k−1
X
j=0
β
j
d(U
1
, U
0
)
≤
β
k
1 −β
d(U
1
, U
0
) .
Therefore, as
k →∞
, we have
d
(
U
l
, U
k
)
→
0, so (
U
k
)
k≥0
is a Cauchy sequence.
By completeness of (
M, d
), (
U
k
)
k≥0
has a limit
U
∗
∈ M
. Finally, for any
k >
0,
we have
d(U
∗
, OU
∗
) ≤d(U
∗
, U
k
) + d(U
k
, OU
∗
) ≤d(U
∗
, U
k
) + βd(U
k−1
, U
∗
) ,
and as
d
(
U
∗
, U
k
)
→
0, we deduce that
d
(
U
∗
, OU
∗
) = 0. Hence,
U
∗
is the unique
fixed point of O. 4
5.13 Bibliographical Remarks
5.1.
The term “dynamic programming” and the Bellman equation are due to
Bellman (1957b). The relationship between the Bellman equation, value func-
tions, and linear systems of equations is studied at length by Puterman (2014)
and Bertsekas (2012). Bertsekas (2011) provides a treatment of iterative policy
evaluation generalized to matrices other than discounted stochastic matrices.
The advantages of the iterative process are well documented in the field and
play a central role in the work of Sutton and Barto (2018), which is our source
for the term “iterative policy evaluation.”
5.2.
Our notion of a probability distribution representation reflects the common
principle in machine learning of modeling distributions with simple parametric
families of distributions; see, for example, the books by MacKay (2003), Bishop
(2006), Wainwright and Jordan (2008), and Murphy (2012). The Bernoulli
representation was introduced in the context of distributional reinforcement
learning, mostly as a curio, by Bellemare et al. (2017a). Normal approximations
have been extensively used in reinforcement learning, often in Bayesian settings
(Dearden et al. 1998; Engel et al. 2003; Morimura et al. 2010b; Lee et al. 2013).
Similar to Equation 5.10, Morimura et al. (2010a) present a distributional
Bellman operator in terms of cumulative distribution functions; see also Chung
and Sobel (1987).
5.3.
Li et al. (2022) consider what is effectively distributional dynamic program-
ming with the empirical representation; they show that in the undiscounted,
finite-horizon setting with reward distributions supported on finitely many inte-
gers, exact computation is tractable. Our notion of the empirical representation
Draft version.
Distributional Dynamic Programming 155
has roots in particle filtering (Doucet et al. 2001; Robert and Casella 2004;
Brooks et al. 2011; Doucet and Johansen 2011) and is also a representation in
modern variational inference algorithms (Liu and Wang 2016). The NP-hardness
result (properly discussed in Remark 5.2) is new as given here, but Mannor
and Tsitsiklis (2011) give a related result in the context of mean-variance
optimization.
5.4.
Sobel (1982) is usually noted as the source of the Bellman equation for the
variance and its associated operator. The equation plays an important role in
theoretical exploration (Lattimore and Hutter 2012; Azar et al. 2013). Tamar et
al. (2016) study the variance equation in the context of function approximation.
5.5.
The
m
-categorical representation was used in a distributional setting by
Bellemare et al. (2017a), inspired by the success of categorical representations
in generative modeling (van den Oord et al. 2016). Dabney et al. (2018b)
introduced the quantile representation to avoid the inefficiencies in using a fixed
set of evenly spaced locations, as well as deriving an algorithm more closely
grounded in the Wasserstein distances.
Morimura et al. (2010a) used the
m
-particle representation to design a risk-
sensitive distributional reinforcement learning algorithm. In a similar vein,
Maddison et al. (2017) used the same representation in the context of exponen-
tial utility reinforcement learning. Both approaches are closely related to particle
filtering and sequential Monte Carlo methods (Gordon et al. 1993; Doucet et
al. 2001; Särkkä 2013; Naesseth et al. 2019; Chopin and Papaspiliopoulos 2020),
which rely on stochastic sampling and resampling procedures, by contrast to
the deterministic dynamic programming methods of this chapter.
5.6, 5.8.
The categorical projection was originally proposed as an ad hoc solu-
tion to address the need to map the output of the distributional Bellman operator
back onto the support of the distribution. Its description as the expectation of a
triangular kernel was shown by Rowland et al. (2018), justifying its use from
a theoretical perspective and providing the proof of Proposition 5.14. Lemma
5.16 is due to Dabney et al. (2018b).
5.7, 5.9–5.10.
The language and analysis of projected operators is inherited
from the theoretical analysis of linear function approximation in reinforcement
learning; a canonical exposition may be found in Tsitsiklis and Van Roy (1997)
and Lagoudakis and Parr (2003). Because the space of probability distributions
is not a vector space, the analysis is somewhat different and, among other
things, requires more technical care (as discussed in Chapter 4). A version of
Theorem 5.28 in the special case of CDP appears in Rowland et al. (2018). Of
note, in the linear function approximation setting, the main technical argument
revolves around the noncontractive nature of the stochastic matrix
P
π
in a
Draft version.

156 Chapter 5
weighted
L
2
norm, whereas here it is due to the
c
-homogeneity of the analysis
metric (and does not involve P
π
). See Chapter 9.
5.11.
A discussion of the mean-preserving property is given in Lyle et al. (2019).
5.14 Exercises
Exercise 5.1.
Suppose that a Markov decision process is acyclic, in the sense
that for any policy π and nonterminal state x ∈X,
P
π
X
t
= x | X
0
= x
= 0 for all t > 0 .
Consider applying iterative policy evaluation to this MDP, beginning with the
initial condition
V
(
x
∅
) = 0 for all terminal states
x
∅
∈X
. Show that it converges
to V
π
in a finite number of iterations K, and give a bound on K. 4
Exercise 5.2.
Show that the normal representation (Definition 5.10) is closed
under the distributional Bellman operator T
π
under the following conditions:
(i) the policy is deterministic: π(a | x) ∈{0, 1};
(ii) the transition function is deterministic: P
X
(x
0
| x, a) ∈{0, 1}; and
(iii) the rewards are normally distributed, P
R
(· | x, a) = N(µ
x,a
, σ
2
x,a
). 4
Exercise 5.3.
In Algorithm 5.1, we made use of the fact that the return
G
π
(
x
∅
)
from the terminal state x
∅
is 0, arguing that this is a more effective procedure.
(i)
Explain how this change affects the output of categorical and quantile
dynamic programming, compared to the algorithm that explicitly maintains
and computes a return-distribution estimate for x
∅
.
(ii)
Explain how this changes affects the analysis given in Section 5.9 onward.
4
Exercise 5.4.
Provide counterexamples showing that if any of the conditions
of the previous exercise do not hold, then the normal representation may not be
closed under T
π
. 4
Exercise 5.5.
Consider a probability distribution
ν ∈P
2
(
R
) with probability
density
f
ν
. For a normal distribution
ν
0
∈F
N
with probability density
f
ν
0
, define
the Kullback–Leibler divergence
KL(ν kν
0
) =
Z
R
f
ν
(z) log
f
ν
(z)
f
ν
0
(z)
dz .
Show that the normal distribution
ˆν
=
N
(
µ, σ
2
) minimizing
KL
(
ν k ˆν
) has
parameters given by
µ = E
Z∼ν
[Z] , σ
2
= E
Z∼ν
[(Z −µ)
2
] . (5.32)
4
Draft version.
Distributional Dynamic Programming 157
Exercise 5.6.
Consider again a probability distribution
ν ∈P
2
(
R
) with instan-
tiation
Z
, and for a normal distribution
ν
0
∈F
N
, define the cross-entropy
loss
CE(ν, ν
0
) = E
Z∼ν
log f
ν
0
(z)
.
Show that the normal distribution
ν
0
that minimizes this cross-entropy loss has
parameters given by Equation 5.32. Contrasting with the preceding exercise,
explain why this result applies irrespective of whether
ν
0
has a probability
density. 4
Exercise 5.7.
Prove Lemma 5.6 from the definition of the pushforward
distribution. 4
Exercise 5.8.
The naive implementation of Algorithm 5.1 requires
O
N
k+1
X
N
k
R
memory to perform the kth iteration. Describe an implementation that reduces
this cost to O
N
X
N
k
R
. 4
Exercise 5.9.
Consider a Markov decision process in which the rewards are
normally distributed:
P
R
(· | x, a) = N
µ(x, a), σ
2
(x, a)
, for x ∈X, a ∈A.
Suppose that we represent our distributions with the
m
-categorical representa-
tion, with projection in Cramér distance Π
c
:
η(x) =
m
X
i=1
p
i
(x)δ
θ
i
.
(i) Show that
(Π
c
T
π
η)(x)
=
X
a∈A
X
x
0
∈X
π(a | x)P
X
(x
0
| x, a)
m
X
i=1
p
i
(x
0
) E
π
Π
c
δ
R+γθ
i
| X = x, A = a] .
(ii) Construct a numerical integration scheme that approximates the terms
E
π
Π
c
δ
R+γθ
i
| X = x, A = a]
to ε precision on individual probabilities, for any x, a.
(iii)
Use this scheme to construct a distributional dynamic programming algo-
rithm for Markov decision processes with normally distributed rewards.
What is its per-iteration computational cost?
(iv)
Suppose that the support
θ
1
, . . . , θ
m
is evenly spaced on [
θ
min
, θ
max
], that
σ
2
(
x, a
) = 1 for all
x, a
, and additionally,
µ
(
x, a
)
∈
[(1
−γ
)
θ
min
,
(1
−γ
)
θ
max
].
Analogous to the results of Section 5.10, bound the approximation error
Draft version.

158 Chapter 5
resulting from this algorithm, as a function of
m
,
ε
, the number of iterations
K. 4
Exercise 5.10.
Prove that the deterministic projection of Section 3.5, defined
in terms of a map to two neighboring particles, is equivalent to the triangular
kernel formulation presented in Section 5.6. 4
Exercise 5.11.
Show that each of the representations of Definitions 5.11–5.13 is
complete with respect to
w
p
, for
p ∈
[1
, ∞
]. That is, for
F ∈{F
Q,m
, F
C,m
, F
E,m
}
,
show that if
ν ∈P
p
(
R
) is the limit of a sequence of probability distributions
(ν
k
)
k≥0
∈F , then ν ∈F . 4
Exercise 5.12.
Show that the empirical representation
F
E
(Definition 5.5) is
not complete with respect to the 1-Wasserstein distance. Explain, concretely,
why this causes difficulties in defining a distance-based projection onto
F
E
.
4
Exercise 5.13.
Explain what happens if the inverse cumulative distribution
function
F
−1
ν
is not continuous in Lemma 5.16. When does that arise? What are
the implications for the w
1
-projection onto the m-quantile representation? 4
Exercise 5.14.
Implement distributional dynamic programming with the empir-
ical representation in the programming language of your choice. Apply it to the
deterministic Markov decision process depicted in Figure 5.6, for a finite num-
ber of iterations
K
, beginning with
η
0
(
x
) =
δ
0
. Plot the supremum 1-Wasserstein
distance between the iterates η
k
and η
π
as a function of k. 4
Exercise 5.15.
Prove that the
m
-categorical representation
F
C,m
is convex and
complete with respect to the Cramér distance
2
, for all m ∈N
+
. 4
Exercise 5.16.
Show that the projected Bellman operator, instantiated with the
m
-quantile representation
F
Q,m
and the
w
1
-projection, is not a contraction in
w
1
. 4
Exercise 5.17.
Consider the metric space given by the open interval (0
,
1)
equipped with the Euclidean metric on the real line, d(x, y) = |x −y|.
(i) Show that this metric space is not complete.
(ii)
Construct a simple contraction map on this metric space that has no fixed
point, illustrating the necessity of the condition of completeness in Banach’s
fixed-point theorem. 4
Exercise 5.18. Let p =
√
2
2
, and consider the probability distribution
ν = (1 − p)δ
0
+ pδ
1
.
Draft version.
Distributional Dynamic Programming 159
Show that, for all
m ∈N
+
, the projection of
ν
onto the
m
-quantile representation,
written Π
q
ν, is such that
w
∞
(Π
q
ν, ν) = 1 .
Comment on the utility of the supremum-
w
∞
metric in analyzing the conver-
gence and the quality of the fixed point of quantile dynamic programming.
4
Exercise 5.19. Consider the Bernoulli representation:
{pδ
0
+ (1 − p)δ
1
: p ∈[0, 1]};
this is also the categorical representation with
m
= 2,
θ
1
= 0,
θ
2
= 1. Consider the
distributional dynamic programming obtained by combining this representation
with a w
∞
-projection.
(i) Describe the projection operator mathematically.
(ii)
Consider a two-state, single-action MDP with states
x, y
with transition
dynamics such that each state transitions immediately to the other and
rewards that are deterministically 0. Show that with
γ >
1
/
2, the distribu-
tional dynamic programming operator defined above is not a contraction
mapping and in particular has multiple fixed points. 4
Exercise 5.20.
The purpose of this exercise is to develop a guarantee of the
approximation error incurred by the fixed point
ˆη
π
q
of the projected distributional
Bellman operator Π
q
T
π
and the
m
-quantile representation; a version of this
analysis originally appeared in Rowland et al. (2019). Here, we write
P
B
(
R
)
for the space of probability distributions bounded on [V
min
, V
max
].
(i)
For a distribution
ν ∈P
B
(
R
) and the quantile projection Π
q
:
P
1
(
R
)
→
F
Q,m
, show that we have
w
1
(Π
q
ν, ν) ≤
V
max
−V
min
2m
.
(ii)
Hence, using the triangle inequality, show that for any
ν, ν
0
∈P
B
(
R
), we
have
w
1
(Π
q
ν, Π
q
ν
0
) ≤w
1
(ν, ν
0
) +
V
max
−V
min
m
.
Thus, while Π
q
is not an nonexpansion under w
1
, per Exercise 5.16, it is in
some sense “not far” from satisfying this condition.
(iii)
Hence, using the triangle inequality with the return functions
ˆη
π
q
,
Π
q
η
π
, and
η
π
, show that if η
π
∈P
B
(R)
X
, then we have
w
1
(ˆη
π
q
, η
π
) ≤
3(V
max
−V
min
)
2m(1 −γ)
.
Draft version.

160 Chapter 5
(iv)
Finally, show that
w
1
(
ν, ν
0
)
≤w
∞
(
ν, ν
0
) for any
ν, ν
0
∈P
B
(
R
). Thus, starting
from the observation that
w
1
(η
k
, η
π
) ≤w
1
(η
k
, ˆη
π
q
) + w
1
(ˆη
π
q
, η
π
) ,
deduce that
w
1
(η
k
, η
π
) ≤γ
k
(V
max
−V
min
) +
3(V
max
−V
min
)
2m(1 −γ)
. 4
Exercise 5.21.
The aim of this exercise is to fill out the details in the reduction
described in Remark 5.2.
(i)
Consider an MDP where
r
(
x, a
)
>
0 is the (deterministic) reward received
from choosing action
a
in state
x
(that is, the distribution
P
R
(
· | x, a
) is a
Dirac delta at
r
(
x, a
)). Deduce that if the values
r
(
x, a
) are distinct across
state-action pairs and that the discount factor γ satisfies
γ <
R
min
R
min
+ R
max
then there is an injective mapping from trajectories to returns.
(ii)
Hence, show that for the class of MDPs described in Remark 5.2, the
trajectories whose returns lie in the set
[
σ∈S
n
n−1
X
t=0
γ
t
σ(t + 1) + γ
n
σ(1),
n−1
X
t=0
γ
t
σ(t + 1) + γ
n
(σ(1) + 1)
are precisely the trajectories whose initial
n
+ 1 states correspond to a
Hamiltonian cycle. 4
Draft version.